
Il y a quelques années nous avons commencé à réorienter nos efforts de développement de nos agents de supervision AllDB vers l’identification des problèmes de performance, parce que c’est finalement le fond de notre travail au quotidien, et que cela nécessite non seulement des compétences, mais aussi des outils de trace et de suivi des requêtes consommatrices. L’idée était de pouvoir identifier visuellement et le plus simplement possible un point de contention, selon plusieurs critères et récupérer suffisamment d’informations pour pouvoir rapidement commencer une analyse sans avoir à se connecter à l’environnement concerné. Ces concepts ont donné ce que nous avons appelé par la suite le palmarès de requêtes, et qui a été intégré à tous nos agents, pour Oracle, SQL Server, MySQL, PostgreSQL et MongoDB.
Une raison supplémentaire nous a poussé dans cette direction : la volonté galopante qu’ont les entreprises de migrer leurs bases de données on-premise vers des services managés du cloud (GCP, Amazon RDS, Azure, et les autres). La cruelle réalité est que l’on ne gagne pas toujours en performance à passer dans le cloud. Et si les clouders vous vantent les mérites de l’élasticité du cloud, votre portefeuille lui n’est pas élastique à l’infini. Il vous faut des outils d’analyse et de compréhension des problèmes de performance pour pouvoir maintenir un contrôle FINOPS sur les périmètres que vous avez déployé, sinon c’est l’escalade, et sous la pression la tentation de toujours ajouter des ressources pour débloquer l’activité.
Aujourd’hui je propose de présenter les fonctionnalités du palmarès pour SQL Server, et nous partirons ensuite d’un cas concret d’incident anonymisé pour voir comment on arrive avec un tel outil à mettre le doigt rapidement sur la requête SQL à l’origine du problème. A noter que contrairement au Query Store, le palmarès SQL Server est compatible à partir de SQL Server 2012, en Standard comme en Enterprise Edition.
Le symptôme :
Lundi matin, une alerte arrive dans la supervision concernant un serveur dans notre périmètre de support, ‘File System sous le seuil‘, et malgré le positionnement de seuil qui nous permet souvent de réagir avant qu’il ne soit trop tard, la saturation est déjà là. On ne vit pas dans un monde parfait, et parfois toutes les sécurités mises en place ne suffisent pas, surtout quand on remplit 230Gb de volume en l’espace de quelques minutes. Il paraît que la nature a horreur du vide :

Rapide corrélation pour associer cette surconsommation d’espace à une utilisation massive d’espace disque dans tempdb (cliquer pour agrandir):

OK donc un traitement a rempli la base tempdb très rapidement et très massivement, ce qui a provoqué une saturation de l’espace disque et une interruption de certains services.
-> Enter the ‘palmarès‘ :
Le palmarès AllDB pour SQL Server propose de regarder le problème de performance selon plusieurs angles différents:
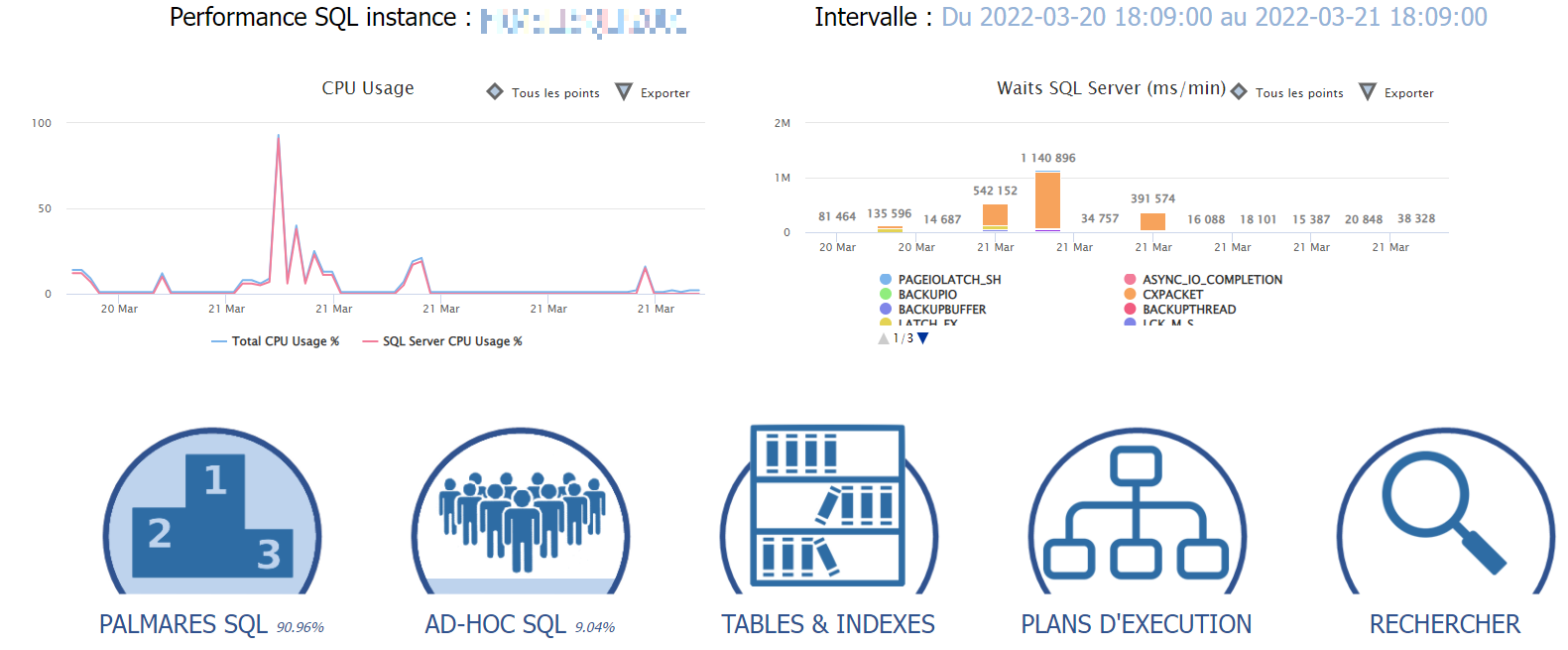
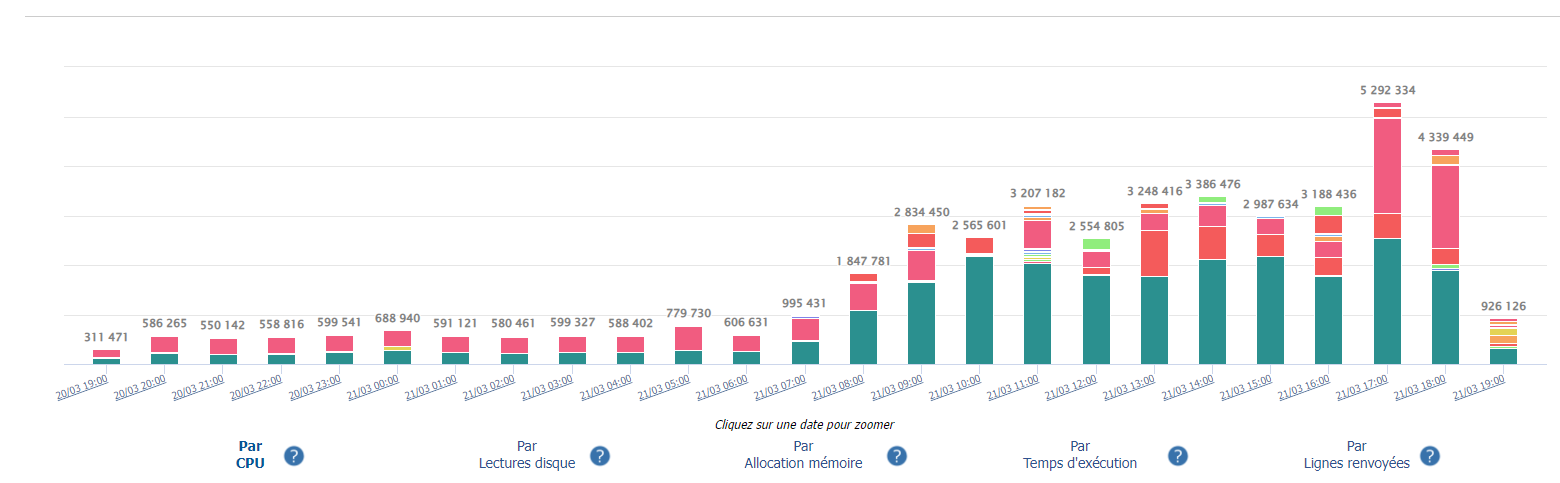
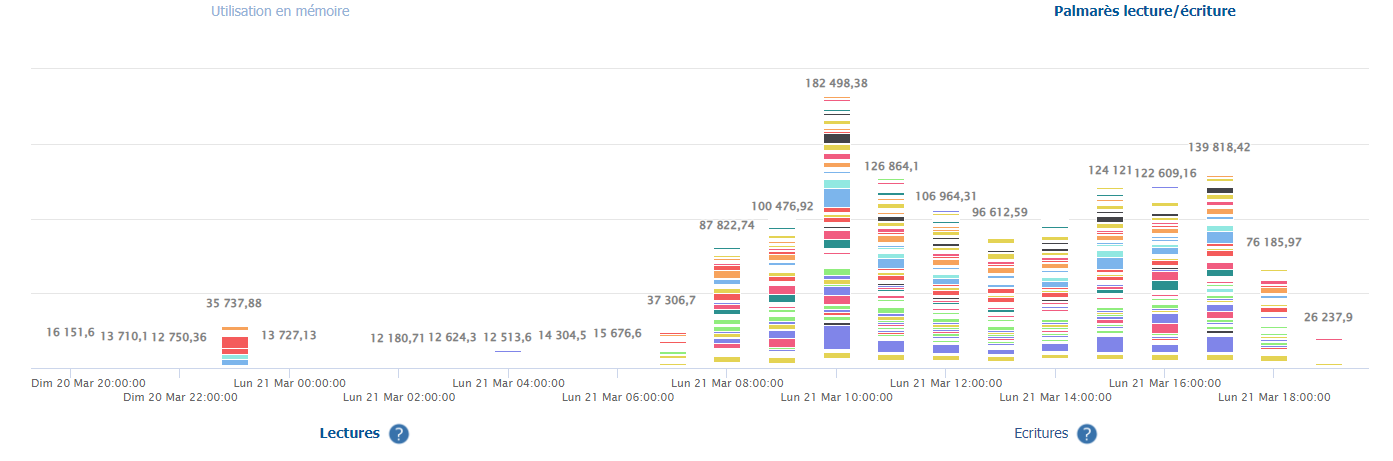
– Palmarès SQL : va rechercher les requêtes normalisées (c’est à dire les requêtes ‘semblables’, sans la partie littérale des arguments de recherche par exemple) qui auront eu le plus d’impact selon un critère (CPU, mémoire, lectures disques, temps d’exécution total, etc…) et sur une période donnée. Chaque histogramme empilé représente une unité de temps, et chaque fraction de cet histogramme une requête (cliquer pour agrandir):
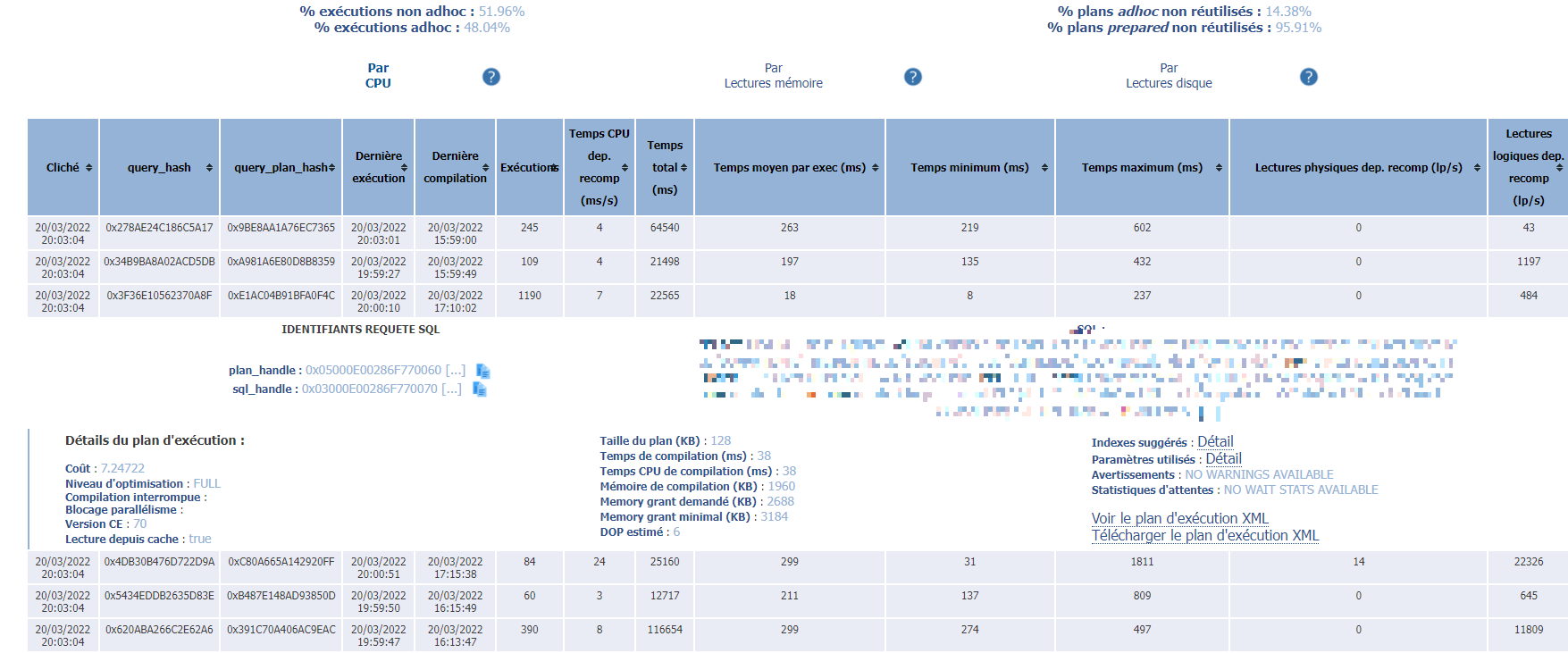
– Ad-Hoc SQL : va simplement remonter le top 10 des requêtes adhoc (donc non normalisées) par cliché et par critère (CPU, lectures disques, lectures logiques) :
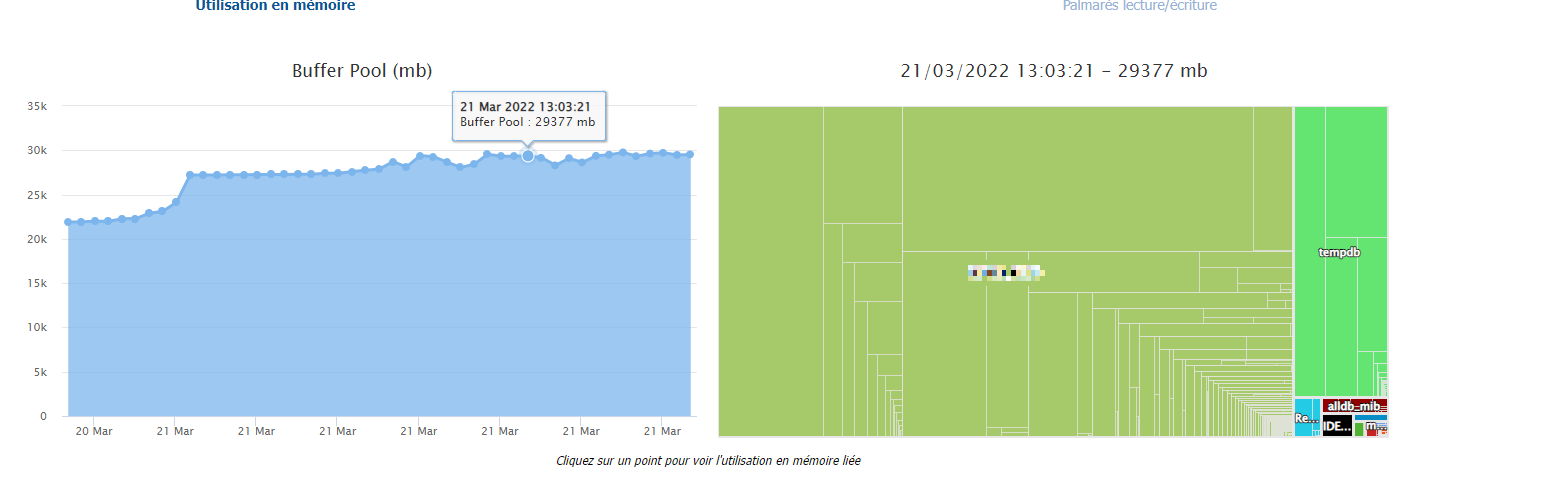
– Tables & Indexes: prend une photo du buffer pool et cartographie son contenu (bases, tables, indexes) et l’évolution au cours du temps:
Dans une autre vue, il calcule aussi un palmarès mais des objets cette fois, en lecture ou en écriture, et là aussi sous la forme d’histogrammes empilés:
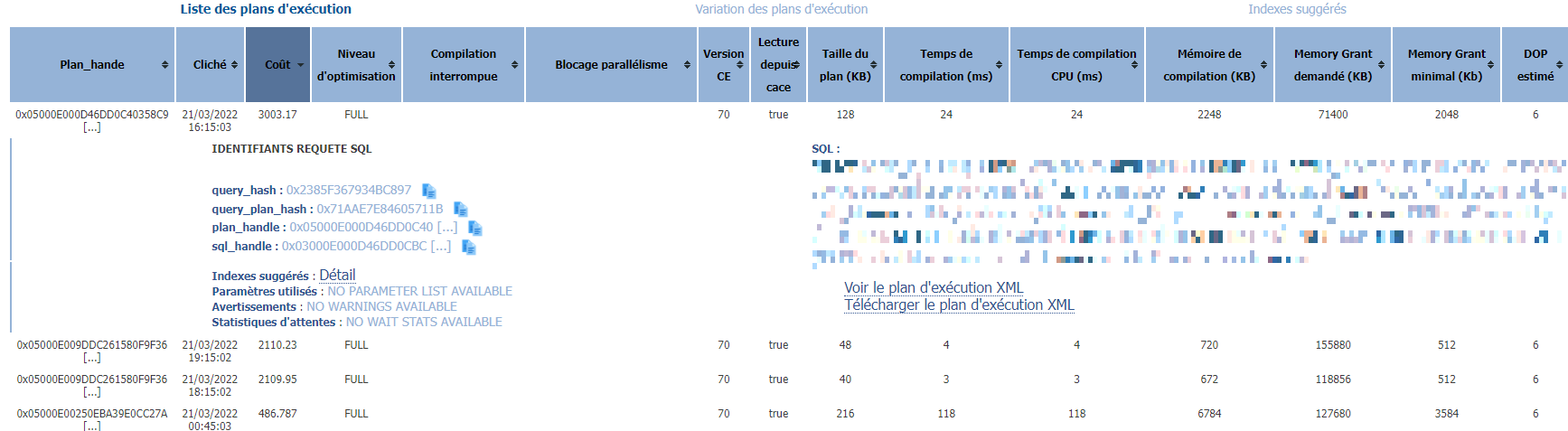
– Plans d’exécution : aborde le problème par les plans: quels sont les plans les plus coûteux ?
Quelles sont les préconisations de placement d’index ?

De quelle manière une même requête peut utiliser différents plans et ainsi mettre en évidence les variations de performance en passant d’un plan à l’autre ?
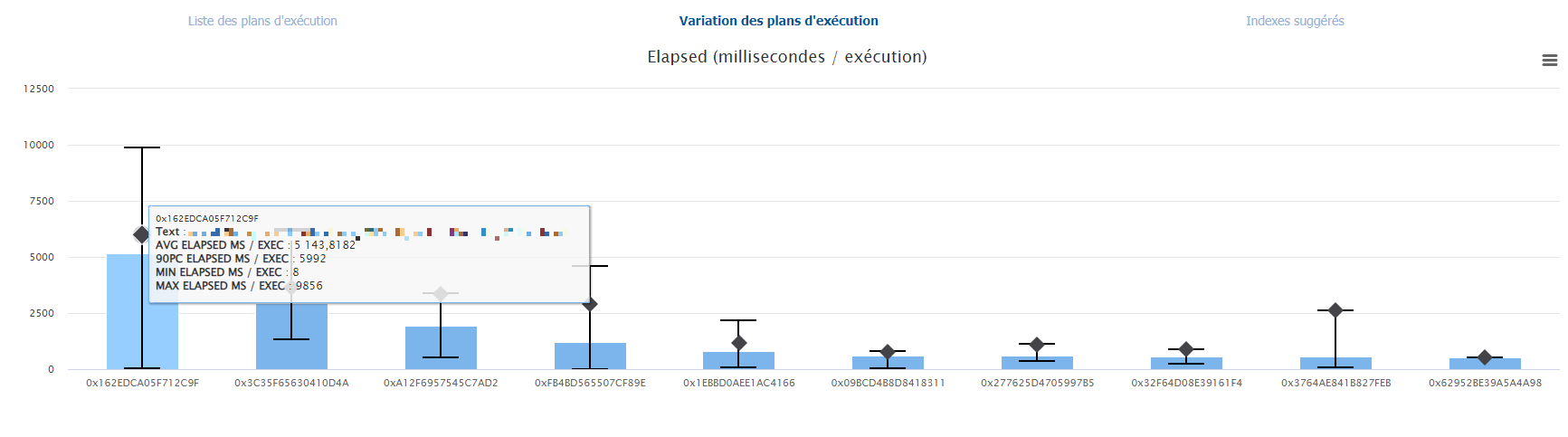
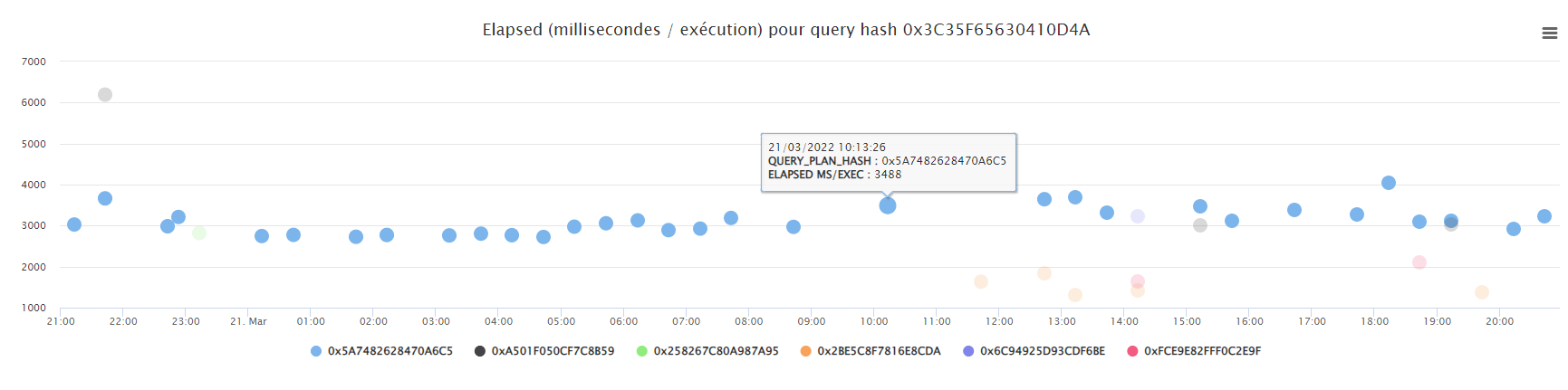
Sur la sélection d’une requête, on peut visualiser les différents plans qu’elle a utilisé, quels sont les plus performants:
– Recherche : comme on historise tout (plans, opérateurs, objets, requêtes, advisors…) on peut faire une recherche ensuite sur tous ces critères et retrouver dans quelles sections ils sont apparus.
Pour revenir à notre problème de tempdb…
Parmi les nombreuses causes qui peuvent être à l’origine d’un remplissage de tempdb, il y a notamment le risque d’erreur d’estimation des cardinalités dans un plan qui peut conduire à sous-évaluer le besoin en mémoire (aka Query Memory Grants). SQL Server aura besoin d’allouer de la mémoire à l’exécution d’une requête pour gérer les tris, opérateurs de parallélisme ou opérateurs Hash (Hash Match, Hash Join). S’il se trompe sur son estimation de lignes, il va demander, disons 100Mb parce qu’il s’attend à trier 1000 lignes, mais en réalité il est possible qu’il doive trier 10 millions de lignes.
Dans ce cas de figure il a demandé trop peu de mémoire au moment de la compilation de son plan, et va devoir réclamer une rallonge à SQL Server au moment de l’exécution, qui ne pourra pas forcément lui être octroyée. Au final c’est tempdb qui sera mise à contribution plutôt qu’un espace pris dans le buffer pool, avec les conséquences sur la performance que l’on imagine …
Dans le palmarès on peut rechercher les requêtes qui ont nécessité le plus de query memory grants, sur la période de l’incident (palmarès par ‘Allocation mémoire‘):
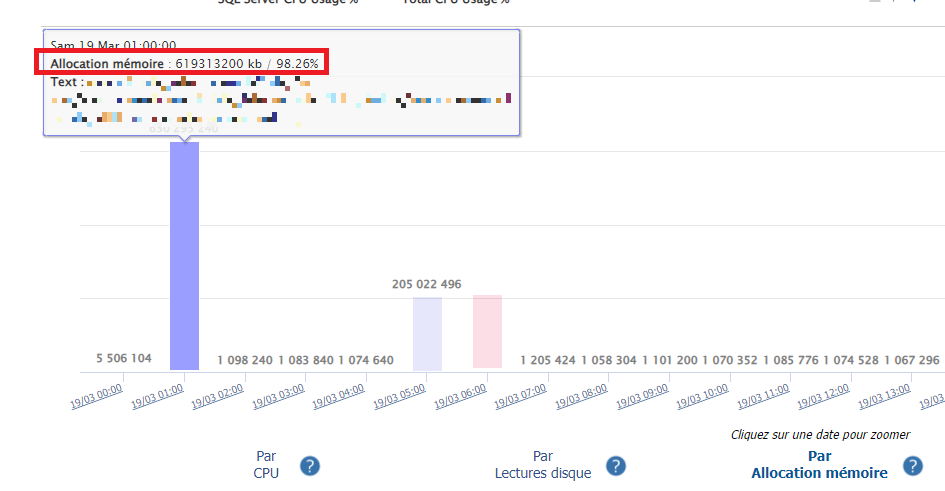
Facile de repérer la requête qui dépasse du lot sur 24 heures, juste à l’heure de notre remplissage, avec un superbe 619Gb de query memory grants cumulés certes et on le verra plus loin sur 556 exécutions, mais quand même. Le buffer pool disposant de 117Gb de mémoire, il y a des chances pour qu’il ne puisse pas servir la totalité de ce qui est demandé, et donc le reste va aller dans tempdb sous la forme de stockage interne (internal allocation).
Si on s’intéresse de plus près aux détails de cette requête (cliquer sur l’image pour voir les détails):
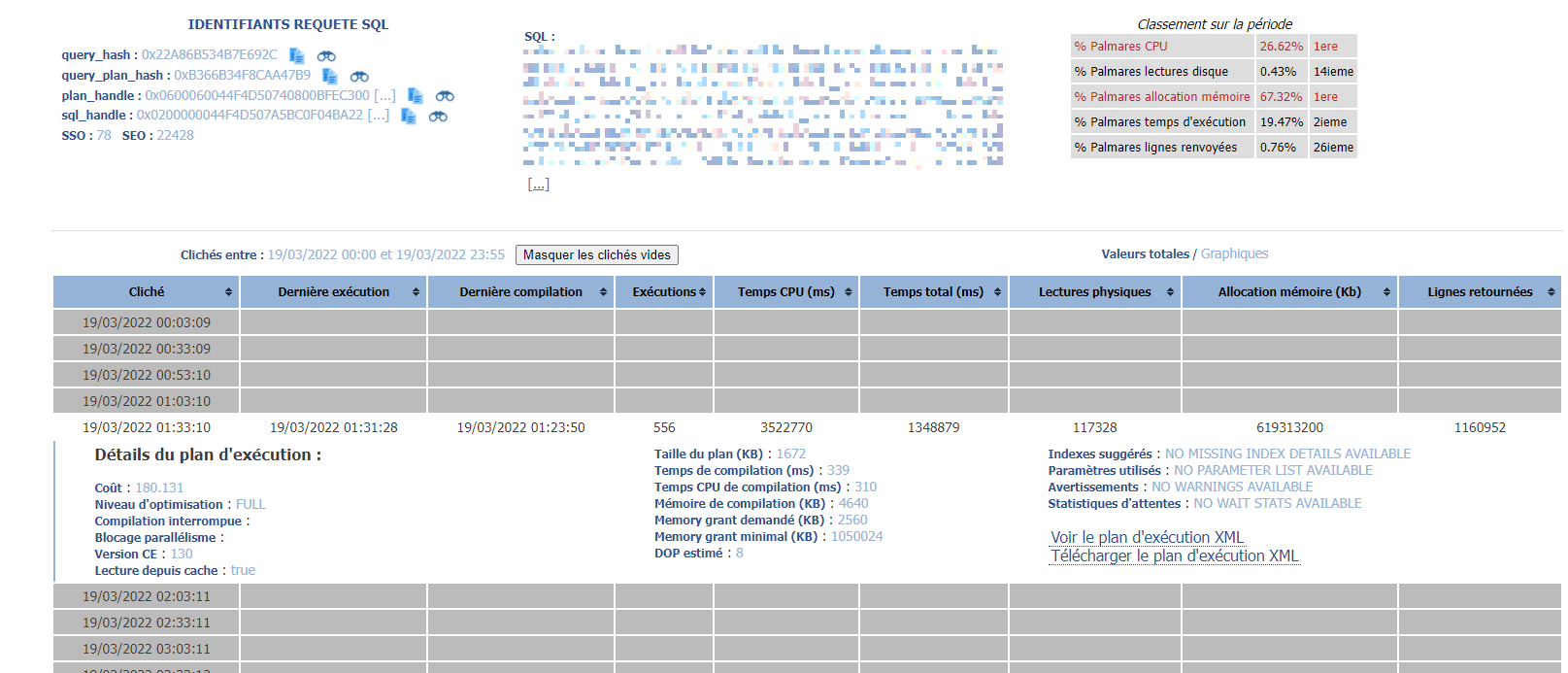
… et que l’on ouvre son plan sous SQL Sentry Plan Explorer :
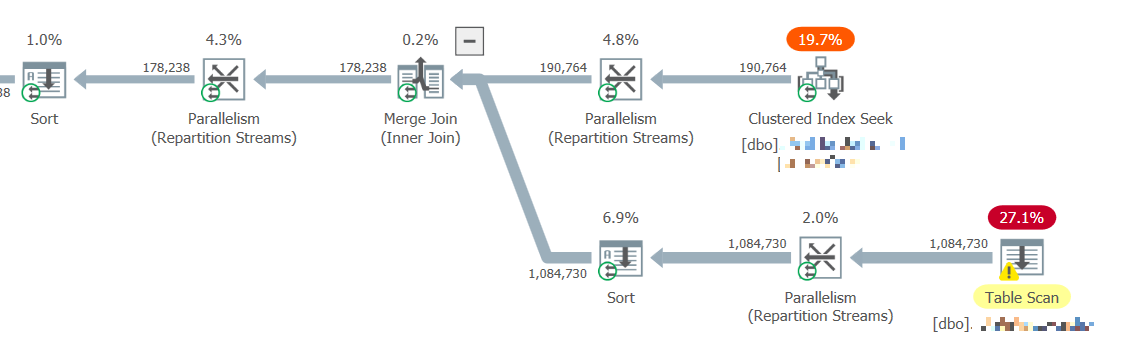
On voit en bas à droite que la table lue est sans index cluster, avec 27% d’impact et un magnifique warning sur des I/Os résiduels qui pourraient résulter du fait que la table doit être lue en intégralité (soit 6.6 millions de lignes réellement et pas 1 million comme estimé):

Dans ce cas, il existe un index unique sur le prédicat mais non clusterisé. Le manque de couverture poussera l’optimiseur à faire un fullscan de la table plutôt qu’un Index Seek accompagné de RID lookups ensuite. La création d’un index cluster unique devrait permettre de couvrir toutes les colonnes demandées et d’éviter ensuite d’avoir à faire des jointures Merge en cascade, à chaque fois nécessitant des tris, ce qui conduit à l’énormissime consommation de Query Memory Grants in fine.
Et tout ça sans avoir à se connecter sur le serveur, dépouiller les DMV, extraire le plan, sortir les cardinalités de la table, etc…
Conclusion : Grâce au palmarès j’ai donné un pronostic au téléphone à mon client en 10 minutes, là où il m’aurait fallu une bonne heure sans cet outil.
Si vous êtes éditeur, cet outil peut également vous aider à mieux appréhender la performance des requêtes que vous développez. Alors si vous voulez une démo du palmarès, n’hésitez pas et contactez-nous !!
A très bientôt alors ?
~David
Continuez votre lecture sur le blog :
- Prochain webcast GUSS 26 juin 19h00 (David Baffaleuf) [SQL Server]
- Vers un DIRECT_PATH_READ sur SQL Server ? (David Baffaleuf) [SQL Server]
- Formation Optimisation de requêtes (David Baffaleuf) [SQL Server]
- DMV et problème de tri (David Baffaleuf) [SQL Server]
- Les nouveautés de SQL Server 2022 (Capdata team) [SQL Server]