
Si vous avez été amené au fil de votre carrière à manipuler de gros volumes de données contenus dans plusieurs tables possédant des références croisées entre elles, dépendantes d’autres tables, qui elles-mêmes dépendent d’autres tables, vous savez à quel point il peut être compliqué de remonter l’intégralité de l’arbre de dépendance pour supprimer la moindre ligne. Cela peut être long et fastidieux.
Vous ne savez pas vraiment ce que vous supprimez, dans quelles tables, et quels impacts cela peut avoir sur votre base de données. Si les dépendances sont nombreuses, il est d’autant plus compliqué de tout retracer et d’être sûr à 100 % de ce que votre DELETE va entraîner.
Dans cet article, je vais vous présenter rapidement un petit outil sous la forme d’une extension que je trouve pratique à utiliser dans ce cas de figure. L’outil s’appelle pg_recursively_delete, et il permet de tracer avant d’exécuter l’ordre de suppression de votre ligne, et d’avoir une arborescence des différentes données que vous allez impacter.
Installation d’un moteur et de l’extension :
Pour cet article, j’ai choisi d’utiliser PostgreSQL en version 16 pour tester si l’extension fonctionnait toujours.
root:~#sudo apt update && sudo apt upgrade root:~#sudo sh -c 'echo "deb http://apt.postgresql.org/pub/repos/apt $(lsb_release -cs)-pgdg main" > /etc/apt/sources.list.d/pgdg.list' root:~#wget --quiet -O - https://www.postgresql.org/media/keys/ACCC4CF8.asc | sudo apt-key add - root:~#sudo apt -y update root:~#sudo apt -y install postgresql-16
Notre moteur de base de données est installé, à présent il nous faut télécharger les sources de l’extension, et l’installer.
root:~# git clone https://github.com/trlorenz/PG-recursively_delete.git Cloning into 'PG-recursively_delete'... remote: Enumerating objects: 155, done. remote: Counting objects: 100% (95/95), done. remote: Compressing objects: 100% (62/62), done. remote: Total 155 (delta 41), reused 74 (delta 29), pack-reused 60 Receiving objects: 100% (155/155), 38.55 KiB | 3.21 MiB/s, done. Resolving deltas: 100% (70/70), done. root:~# cd PG-recursively_delete/ root:~/PG-recursively_delete# make cp sql/recursively_delete.sql sql/recursively_delete--0.1.5.sql root:~/PG-recursively_delete# sudo make install /bin/mkdir -p '/usr/share/postgresql/16/extension' /bin/mkdir -p '/usr/share/postgresql/16/extension' /bin/mkdir -p '/usr/share/doc/postgresql-doc-16/extension' /usr/bin/install -c -m 644 .//recursively_delete.control '/usr/share/postgresql/16/extension/' /usr/bin/install -c -m 644 .//sql/recursively_delete--0.1.5.sql '/usr/share/postgresql/16/extension/' /usr/bin/install -c -m 644 .//doc/changelog.md '/usr/share/doc/postgresql-doc-16/extension/'
Mise en place de l’environnement
Pour illustrer le fonctionnement de l’extension, je vais utiliser la base de données de démonstration dvdrental. Nous allons donc la télécharger et la charger dans une toute nouvelle base de données que nous aurons créée sur notre instance fraîchement créée :
postgres:~$ wget https://www.postgresqltutorial.com/wp-content/uploads/2019/05/dvdrental.zip --2024-03-11 08:34:54-- https://www.postgresqltutorial.com/wp-content/uploads/2019/05/dvdrental.zip Resolving www.postgresqltutorial.com (www.postgresqltutorial.com)... 104.21.2.174, 172.67.129.129, 2606:4700:3037::6815:2ae, ... Connecting to www.postgresqltutorial.com (www.postgresqltutorial.com)|104.21.2.174|:443... connected. HTTP request sent, awaiting response... 200 OK Length: 550906 (538K) [application/zip] Saving to: ‘dvdrental.zip’ dvdrental.zip 100%[========================================================================================================================================>] 537.99K --.-KB/s in 0.01s 2024-03-11 08:34:54 (46.0 MB/s) - ‘dvdrental.zip’ saved [550906/550906]
Une fois téléchargée, on la dezippe :
postgres:~$ ls -l total 544 drwxr-xr-x 3 postgres postgres 4096 Mar 11 08:30 16 -rw-rw-r-- 1 postgres postgres 550906 May 12 2019 dvdrental.zip postgres:~$ unzip dvdrental.zip Archive: dvdrental.zip inflating: dvdrental.tar postgres:~$ ls -l total 3316 drwxr-xr-x 3 postgres postgres 4096 Mar 11 08:30 16 -rw-rw-r-- 1 postgres postgres 2835456 May 12 2019 dvdrental.tar -rw-rw-r-- 1 postgres postgres 550906 May 12 2019 dvdrental.zip
On créé la base de données pour accueillir nos données, et on charge le fichier de sauvegarde :
postgres:~$ psql psql (16.2 (Ubuntu 16.2-1.pgdg22.04+1)) Type "help" for help.
postgres=# create database dvdrental;
CREATE DATABASE
postgres=# \l
List of databases
Name | Owner | Encoding | Locale Provider | Collate | Ctype | ICU Locale | ICU Rules | Access privileges
-----------+----------+----------+-----------------+---------+---------+------------+-----------+-----------------------
dvdrental | postgres | UTF8 | libc | C.UTF-8 | C.UTF-8 | | |
postgres | postgres | UTF8 | libc | C.UTF-8 | C.UTF-8 | | |
template0 | postgres | UTF8 | libc | C.UTF-8 | C.UTF-8 | | | =c/postgres +
| | | | | | | | postgres=CTc/postgres
template1 | postgres | UTF8 | libc | C.UTF-8 | C.UTF-8 | | | =c/postgres +
| | | | | | | | postgres=CTc/postgres
(4 rows)postgres:~$ pg_restore -U postgres -d dvdrental dvdrental.tar
Une fois que c’est fait, on peut se connecter pour vérifier que tout a bien été chargé :
postgres:~$ psql psql (16.2 (Ubuntu 16.2-1.pgdg22.04+1)) Type "help" for help.
postgres=# \c dvdrental
You are now connected to database "dvdrental" as user "postgres".
dvdrental=# \dt
List of relations
Schema | Name | Type | Owner
--------+---------------+-------+----------
public | actor | table | postgres
public | address | table | postgres
public | category | table | postgres
public | city | table | postgres
public | country | table | postgres
public | customer | table | postgres
public | film | table | postgres
public | film_actor | table | postgres
public | film_category | table | postgres
public | inventory | table | postgres
public | language | table | postgres
public | payment | table | postgres
public | rental | table | postgres
public | staff | table | postgres
public | store | table | postgres
(15 rows)
L’extension :
Pour tester l’extension, nous allons essayer de supprimer un client de la liste des clients.
Le schéma de la base de données dvdrental est le suivant :
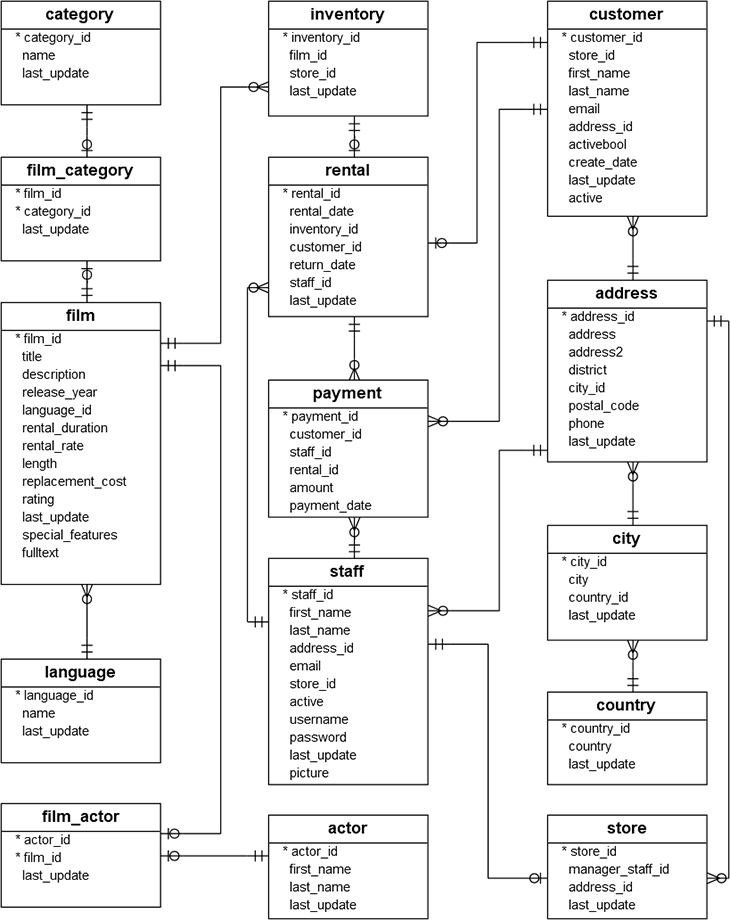
Si l’on observe attentivement le schéma ci-dessus, en voulant supprimer une donnée de la table customer, cela devrait avoir un impact sur les tables rental et payment qui sont directement liées à la table customer. De plus, ces deux tables sont également liées entre elles, ce qui signifie que supprimer une donnée dans la table rental modifiera nécessairement la table payment.
Prenons l’exemple de la suppression du client numéro 1. Si nous recherchons les dépendances de ce client dans la table rental, nous obtenons 32 lignes associées au customer_id 1 :
dvdrental=# select count(*) from rental where customer_id = 1;
count
-------
32
(1 row)
Et si nous allons maintenant chercher toutes les occurrences de ce même client dans la table des paiements, nous obtenons :
dvdrental=# select count(*) from payment where customer_id = 1;
count
-------
30
(1 row) À présent, avec l’extension recursive_delete, nous allons chercher à obtenir le schéma de suppression pour vérifier si les résultats que nous avons trouvés sont corrects :
dvdrental=# create extension recursively_delete;
CREATE EXTENSION
dvdrental=# \set VERBOSITY terse
dvdrental=# select recursively_delete('customer', 1);
INFO: DAMAGE PREVIEW (recursively_delete v0.1.5)
INFO:
INFO: 1 customer
INFO: 30 r | payment.["customer_id"]
INFO: 32 r | rental.["customer_id"]
INFO: ~ n | | payment.["rental_id"]
INFO:
recursively_delete
--------------------
0
(1 row) La fonction de suppression de l’extension fonctionne avec les paramètres suivants :
- Le nom de la table en premier paramètre
- La clause WHERE du DELETE en second paramètre, qui peut être de multiples types (des entiers, des chaînes de caractères, des listes, des UUID…)
- Le mode de fonctionnement de l’extension, par défaut à false, qui indique au programme de ne pas effectuer les suppressions, mais simplement de dresser le schéma. Le passer à true entraînerait les suppressions.
Pour interpréter le schéma, voici la composition de chaque nœud :
- La première colonne correspond au nombre de lignes
- Le type de contraintes qui expliquent l’implication de la table dans le schéma : ‘a’, ‘r’, ‘c’, ‘n’, ou ‘d’ (‘no action’, ‘restrict’, ‘cascade’, ‘set null’, ou ‘set default’)
- Un indicateur de si oui ou non le champ en question participe à une référence circulaire.
En examinant le résultat renvoyé par notre extension, nous constatons que nous obtenons les mêmes résultats : 30 lignes pour payment et 32 lignes pour rental. Nous obtenons également une dernière ligne qui nous indique que payment possède une référence à rental dans sa structure, et qu’il va lui aussi procéder à des suppressions en fonction du rental_id. Cela pourrait être par exemple le cas où une location effectuée par un client serait payée par un autre.
Pour effectuer la suppression, il suffit simplement de préciser true en troisième paramètre.
dvdrental=# select recursively_delete('customer', 1, true);
recursively_delete
--------------------
1
(1 row)
Et à présent, si nous consultons notre table customer, la ligne 1 a disparu, ainsi que toutes les lignes qui la concernent dans d’autres tables également.
dvdrental=# select count(*) from customer where customer_id = 1;
count
-------
0
(1 row)
dvdrental=# select count(*) from rental where customer_id = 1;
count
-------
0
(1 row)
dvdrental=# select count(*) from payment where customer_id = 1;
count
-------
0
(1 row)
Nos lignes ont bel et bien disparu.
Cette extension fonctionne également avec les clés primaires composites. Il suffit de préciser entre crochets les deux valeurs de notre clé primaire, et le tour est joué.
Pour illustrer davantage le fonctionnement, je vais réaliser une suppression sur la table film. Cette table possède quelques dépendances.
Disons que nous souhaitons supprimer les 10 premiers films de notre liste, car ils ne sont plus loués étant trop anciens (plus personne n’a de magnétoscope pour regarder de bonnes vieilles cassettes !).
dvdrental=# select recursively_delete('film', (SELECT array_agg(film_id) FROM film WHERE film_id between 1 and 10));
INFO: DAMAGE PREVIEW (recursively_delete v0.1.5)
INFO:
INFO: 10 film
INFO: 62 r | film_actor.["film_id"]
INFO: 10 r | film_category.["film_id"]
INFO: 52 r | inventory.["film_id"]
INFO: 165 r | | rental.["inventory_id"]
INFO: ~ n | | | payment.["rental_id"]
INFO:
recursively_delete
--------------------
0
(1 row)Nous observons donc que notre suppression de 10 films (dans un array) entraîne la suppression d’acteurs, de catégories, d’inventaires, et par extension, de locations et de paiements
Conclusion :
En conclusion, l’extension pg_recursively_delete offre une solution pratique pour supprimer récursivement des données dans PostgreSQL, simplifiant ainsi les tâches de maintenance et de nettoyage des bases de données. Cependant, malgré ses avantages, cette extension présente certaines limites en termes de performances.
L’une des principales limitations réside dans le fait que la suppression récursive peut entraîner des opérations coûteuses en termes de temps d’exécution, surtout lorsque les données concernées sont fortement imbriquées ou que la base de données est volumineuse. Les performances peuvent également être affectées lorsque les tables impliquées dans la suppression ont des index complexes ou des contraintes de clés étrangères.
De plus, il est crucial de reconnaître les risques associés à la suppression de données ayant de nombreuses dépendances dans une base de données. La suppression inconsidérée de telles données peut entraîner des incohérences dans la base de données, des erreurs d’intégrité référentielle et même des pertes de données importantes. Il est donc essentiel de procéder avec prudence et de prendre en compte toutes les implications potentielles avant d’utiliser cette extension.
En résumé, bien que l’extension pg_recursively_delete offre une fonctionnalité utile pour gérer les opérations de suppression récursive dans PostgreSQL, il est essentiel pour les utilisateurs de comprendre ses limites en termes de performances et les risques potentiels associés à la suppression de données avec de nombreuses dépendances. Une utilisation judicieuse et une évaluation minutieuse des scénarios d’utilisation sont indispensables pour garantir l’intégrité et la performance de la base de données.
Continuez votre lecture sur le blog :
- pg_dirtyread où comment réparer facilement un delete sauvage (Sarah FAVEERE) [PostgreSQL]
- Pyrseas et Postgresql : Comparer facilement des schémas de base de données (Sarah FAVEERE) [PostgreSQL]
- PostgreSQL : planifier une tâche avec pg_cron (Emmanuel RAMI) [Non classéPostgreSQL]
- PostgreSQL Anonymizer (Sarah FAVEERE) [PostgreSQL]
- La montée de version en zero-downtime : merci la réplication ! (Sarah FAVEERE) [PostgreSQL]