
Introduction :
Quand une requête PostgreSQL est considérée comme lente ou que ses performances se dégradent soudainement, il y a un réflexe à toujours avoir : utiliser les plans d’exécution. Je n’apprends certainement rien à la majorité des personnes qui liront cet article, mais si cela permet de garder vigilants les débutants et de leur enseigner quelques ficelles, alors cet article vaut le coup.
Si vous avez déjà été dans le cas de figure où un plan d’exécution est trop gros pour que vous sachiez par quel bout le prendre, ou si vous avez l’impression qu’on vous parle chinois quand on évoque les index scan ou les “cost” d’une requête, alors vous êtes au bon endroit.
Dans cet article, premier d’une série sur les bases de PostgreSQL, nous allons démystifier l’optimisation des requêtes en utilisant EXPLAIN comme point de départ, et les plans d’exécution générés comme fil conducteur.
L’objectif : vous aider à identifier rapidement les informations clés, repérer les goulots d’étranglement, et gagner en autonomie pour diagnostiquer les performances de vos requêtes.
C’est parti !
EXPLAIN ANALYZE : c’est quoi exactement et pourquoi l’utiliser ?
Pour commencer, il faut savoir qu’un moteur de base de données, que ce soit PostgreSQL ou un autre ne “lit” pas une requête comme un humain pourrait la lire, de gauche à droite. Il élabore plutôt un plan d’exécution : il créé un ensemble d’étape qui se veulent le plus optimisées possible pour aller chercher les données que vous lui demander de la façon la plus efficace possible.
Il y a un moyen simple de voir ce plan d’exécution, c’est d’utiliser la commande EXPLAIN ANALYZE. Elle nous permet en plus de comprendre de quelle façon le moteur à réellement exécuté notre ordre SQL (et pas seulement comment il pensait le faire). C’est un peu comme lire un journal de bord de l’exécution de la requête.
Prenons un exemple simple :
Imaginons que nous avons une table users, constituée comme tel :
CREATE TABLE users ( id integer PRIMARY KEY, name vachar(30), age integer, email varchar(80) );
Et que nous souhaitons utiliser la requête suivante dans notre application :
SELECT * FROM users WHERE email = 'foo@example.com';
Sur cette table, nous n’avons pas d’index. Voici donc ce à quoi pourrait ressembler notre plan d’éxecution si nous utilisons la commande :
EXPLAIN ANALYZE SELECT * FROM users WHERE email = 'foo@example.com'; Seq Scan on users (cost=0.00..35.50 rows=1 width=100) Filter: (email = 'foo@example.com') Rows Removed by Filter: 999 Actual time=0.010..0.420 rows=1 loops=1
Les termes du plan d’exécution :
A première vue, il n’est pas évident de comprendre tout les termes que l’on voit dans le plan d’exécution généré.
Voici un récapitulatif des principaux :
- Seq Scan / Index Scan : Le type de parcours utilisé (séquentiel ou via un index)
- cost=… : Estimation du “coût” total de l’opération, selon PostgreSQL. Le coût n’est pas exprimé dans une unité particulière, c’est juste un indicatif. Plus il est élevé, plus l’opération est “coûteuse”, notre but étant d’éviter les coûts énormes pour que tout soit plus simple.
- rows=… : Estimation du nombre de lignes que l’étape va retourner
- actual time=… : Le temps réel que cette étape a pris (en millisecondes)
- Rows Removed by Filter : Nombre de lignes lues mais éliminées par un filtre
- loops=1 : Nombre de fois que cette étape a été exécutée (ex. dans une boucle)
Puis un exemple plus compliqué :
Attention, tout les plans d’exécution de requête ne sont pas aussi simples que celui que je viens de vous présenter. Bien souvent ils se présentent sous la forme de plusieurs nœuds indentés qu’il faut lire dans le bon ordre. Imaginons une nouvelle table orders qui répertorie les commandes passées par un user :
CREATE TABLE orders ( id_orders integer PRIMARY KEY, created_at timestamp, total numeric, status text, user_id integer references users(id));
Nous pouvons alors imaginer la requête suivante :
SELECT u.name, o.total, o.created_at FROM users u JOIN orders o ON u.id = o.user_id WHERE o.status = 'completed' ORDER BY o.created_at DESC LIMIT 10;
Qui remonte les dix premières commandes, avec le nom de l’acheteur, le total de la commande et sa date, pour les 10 premières commandes dans l’ordre des dates dont le statut est “completed”.
Si on execute un explain analyze sur cette requête, on obtient un plan d’execution de cet ordre :
Limit (cost=123.45..123.48 rows=10 width=40) (actual time=1.234..1.239 rows=10 loops=1)
-> Sort (cost=123.45..130.00 rows=2620 width=40) (actual time=1.234..1.236 rows=10 loops=1)
Sort Key: o.created_at DESC
Sort Method: top-N heapsort Memory: 25kB
-> Nested Loop (cost=0.42..100.00 rows=2620 width=40) (actual time=0.045..0.980 rows=200 loops=1)
-> Index Scan using idx_orders_created_at on orders o (cost=0.29..45.00 rows=2620 width=24) (actual time=0.030..0.340 rows=200 loops=1)
Filter: (status = 'completed')
Rows Removed by Filter: 50
-> Index Scan using users_pkey on users u (cost=0.13..0.20 rows=1 width=16) (actual time=0.003..0.004 rows=1 loops=200)
Index Cond: (id = o.user_id)Si on devait visualiser ce plan d’exécution de manière graphique pour qu’il soit plus simple à lire, ça donnerait ça :
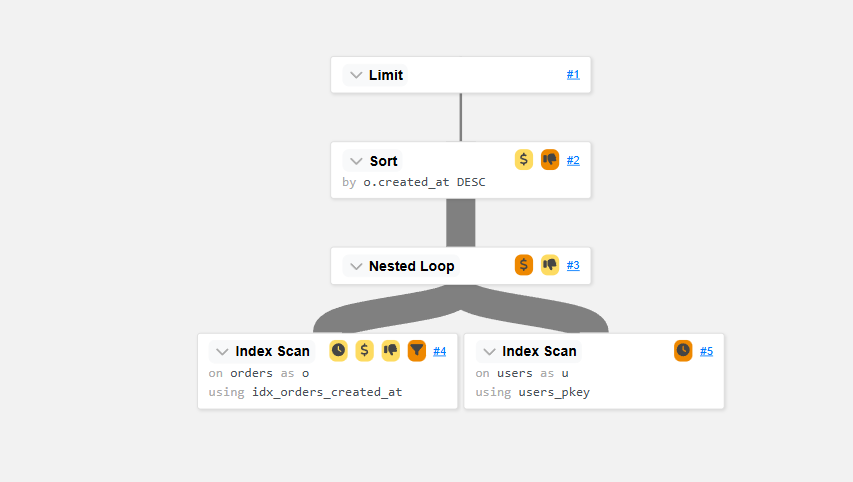
Comment lire un plan d’exécution :
Pour lire un plan d’exécution, on part toujours du nœud le plus indenté, puis on remonte vers les nœuds supérieur. Dans notre cas, on partirais des deux index scan pour remonter ensuite sur le Nested Loop, puis sur le Sort, et enfin sur le Limit.
La raison est simple : le plan d’exécution reflète l’ordre réel d’exécution de la requête par PostgreSQL.
Chaque étape du plan consomme les résultats produits par les étapes précédentes. Autrement dit : PostgreSQL commence par les opérations de lecture (accès aux tables, scans d’index…), puis applique les jointures, les filtres, les tris, etc. en remontant vers le haut du plan.
Le nœud le plus “haut” du plan (celui avec le moins d’indentation) correspond à l’opération finale, celle qui retourne les résultats à l’utilisateur. Les blocs en dessous (plus indentés) sont les dépendances nécessaires pour y arriver.
C’est donc une logique de pipeline de traitement :
- Lire les données
- Les filtrer
- Les combiner
- Les trier / agréger
- Les retourner
Lire un plan d’exécution “du plus profond vers le haut”, c’est suivre le chemin de vie d’une ligne de résultat depuis le disque jusqu’à votre terminal.
Petite encyclopédie des nœuds les plus courants dans un plan d’exécution
Voici une sélection des nœuds que vous croiserez régulièrement dans les plans d’exécution PostgreSQL, avec une explication simple et directe pour chacun :
Seq Scan
Lecture séquentielle de toute la table.
À surveiller : Normal sur petites tables, mais sur les grosses, cela peut indiquer un index manquant.Index Scan
Parcours d’un index pour chercher les lignes correspondantes.
À surveiller : Rapide si l’index est bien choisi. Peut devenir lent avec beaucoup de loops.Index Only Scan
Comme un Index Scan, mais sans lire la table si toutes les colonnes nécessaires sont déjà dans l’index.
À surveiller : Ultra-performant ! À viser si possible.Bitmap Index Scan + Bitmap Heap Scan
PostgreSQL construit une “carte” des lignes à lire, puis les récupère en une seule passe.
À surveiller : Très performant pour des filtres avec beaucoup de résultats.Nested Loop
Pour chaque ligne de la première table, PostgreSQL cherche dans la seconde.
À surveiller : Bien sur de petits volumes, mais peut exploser sur de grandes tables (effet quadratique).Hash Join
PostgreSQL construit une table de hachage en mémoire pour faire la jointure.
À surveiller : Performant si la mémoire le permet. Attention à la taille des jeux de données.Merge Join
Jointure optimisée entre deux sources déjà triées.
À surveiller : Excellent en perfs si les colonnes jointes sont indexées ou triées à l’avance.Aggregate
Calcule une agrégation (COUNT, SUM, AVG, …).
À surveiller : Peut être coûteux si l’agrégation se fait sur de gros volumes sans index.Sort
Trie les données selon une ou plusieurs colonnes.
À surveiller : Peut consommer beaucoup de mémoire ; un bon index peut éviter cette étape.Limit
Tronque le résultat à N lignes.
À surveiller : Très utile combiné avec ORDER BY, car PostgreSQL peut s’arrêter dès qu’il a assez de lignes triées.CTE Scan
Utilisé quand vous avez une clause WITH (CTE – Common Table Expression).
À surveiller : Si le CTE n’est pas matérialisé, il peut être recalculé à chaque appel.
Options utiles de EXPLAIN / EXPLAIN ANALYZE
La commande EXPLAIN (et sa variante EXPLAIN ANALYZE) peut être enrichie avec plusieurs options facultatives pour mieux comprendre ce que PostgreSQL fait avec vos requêtes. Voici une présentation des principales.
ANALYZE : exécuter la requête pour de vrai
Cette option (souvent appelée “EXPLAIN ANALYZE”) exécute réellement la requête et mesure les temps d’exécution.
EXPLAIN ANALYZE SELECT * FROM users WHERE email = 'foo@example.com';
Sans cette option, PostgreSQL ne fait qu’estimer le plan, il ne l’exécute pas réellement.
VERBOSE: plus de détails sur les colonnes et les expressions
Affiche le nom exact des colonnes internes et les expressions utilisées dans chaque étape du plan.
EXPLAIN (ANALYZE, VERBOSE) SELECT name FROM users WHERE age > 30;
Très utile quand on travaille avec des fonctions, des agrégats ou des vues complexes.
BUFFERS : détail des lectures mémoire et disque
Montre combien de blocs de données ont été lus en mémoire (cache partagé) et depuis le disque.
EXPLAIN (ANALYZE, BUFFERS) SELECT * FROM orders WHERE status = 'completed';
Idéal pour identifier si une requête est ralentie par des accès disques trop nombreux.
WAL : suivi des écritures dans le journal de transactions
Affiche l’impact de la requête sur le WAL (Write-Ahead Logging), c’est-à-dire les écritures nécessaires à la durabilité.
EXPLAIN (ANALYZE, WAL) INSERT INTO logs SELECT * FROM events;
Surtout utile pour comprendre le coût caché des requêtes d’écriture.
COSTS : afficher ou masquer les coûts estimés
Permet de désactiver les lignes cost=… si on veut se concentrer uniquement sur les temps réels (actual time).
EXPLAIN (ANALYZE, COSTS OFF) SELECT * FROM users;
Pratique pour alléger la lecture d’un plan quand on n’a pas besoin des estimations.
SETTINGS : voir les paramètres ayant influencé le plan
Affiche les paramètres de configuration de PostgreSQL qui ont eu un impact sur la génération du plan.
EXPLAIN (ANALYZE, SETTINGS) SELECT * FROM users;
Très utile pour le debug avancé, ou si certains paramètres sont modifiés via SET.
SUMMARY : afficher ou non les temps globaux
Contrôle l’affichage du résumé final (Planning Time, Execution Time).
EXPLAIN (ANALYZE, SUMMARY OFF) SELECT * FROM users;
Par défaut activé, mais vous pouvez le désactiver si vous ne souhaitez pas ces infos à la fin du plan.
TIMING : activer ou désactiver la mesure des temps internes
PostgreSQL mesure le actual time pour chaque nœud du plan. Cette option permet de désactiver ces mesures (utile pour les très petites requêtes ou les benchmarks massifs).
EXPLAIN (ANALYZE, TIMING OFF) SELECT * FROM users;
Désactive les mesures fines, ce qui peut légèrement améliorer les performances du plan d’analyse lui-même.
FORMAT : changer la sortie (TEXT, JSON, YAML)
Permet d’obtenir un plan dans un format structuré (parfait pour les outils externes comme explain.dalibo.com).
EXPLAIN (ANALYZE, FORMAT JSON) SELECT * FROM users;
Pratique pour générer un plan visuel, l’analyser en script, ou l’intégrer dans des outils de perf.
OK super, mais une fois qu’on sait ça, on en fait quoi ?
On pourrait passer des heures à décortiquer les différentes lignes d’un plan d’exécution sans pour autant avancer plus que ça. L’important est maintenant de savoir quoi en faire. Parce que c’est bien beau de l’afficher, encore faut-il savoir quoi y chercher.
Voici une petite liste non exhaustive des indices à repérer dans un plan d’exécution qui pourraient vous mener à une raison pour la lenteur de votre requête :
🔎 Une lecture séquentielle sur une grosse table :
Symptôme :
Pourquoi c’est un souci
PostgreSQL lit toute la table ligne par ligne. C’est très lent et parfaitement inutile, surtout si vous ne voulez que quelques lignes de cette table.
Comment le voir
- On note la présence d’un nœud SEQ SCAN dans notre plan d’exécution
- Nombre de lignes parcourues très élevé (puce rows ou présence de row removed by filter)
Solutions
- Ajouter un index sur la colonne filtrée peut souvent aider dans ce genre de cas.
- Réécrire la requête pour qu’elle utilise une clause mieux optimisée (exclusion, inclusion…)
🔎 Trop de Loop
Symptôme :
Pourquoi c’est un souci
Une opération lente est répétée pour chaque ligne de l’opération extérieure, souvent dans une jointure en boucle (Nested Loop).
Comment le voir
- Nombre de loop très élevés
- Souvent précédé d’un Nested Loop plus haut dans le plan d’exécution
Solutions
Changer le type de jointure pour quelque chose de plus simple a traiter (hash join ou merge join)
Réécrire la requête pour faire moins de “aller-retours”
Ajouter des index pour faciliter les jointures
🔎 Des estimations loin de la réalité
Symptôme :
Pourquoi c’est un souci
PostgreSQL s’est trompé dans son estimation, ce qui l’a peut-être mené à choisir un mauvais plan.
Comment le voir
Comparez le nombre de rows (estimation) avec les actual rows. Si l’écart est très important, les statistiques sont probablement obsolètes.
Solutions
Rafraichir les statistiques dans ce cas ne peut pas faire de mal : Analyze ou vaccuum analyze si nécessaire.
Ajuster les statistiques
Éviter les expressions trop complexes qui biaisent les estimations
🔎 Un tri qui consomme trop
Symptôme :
Pourquoi c’est un souci
Le tri est trop gros, PostgreSQL n’arrive plus à le faire en RAM → il passe sur disque → c’est lent.
Comment le voir
Nœud SORT avec un SORT METHOD lent (EXTERNAL MERGE)
Consommation mémoire élevée
Étape qui prend beaucoup de temps
Solutions
Ajouter un index sur les colonnes utilisées dans le ORDER BY
Réduire la quantité de lignes à trier avec un LIMIT en amont
Éviter les sous-requêtes non filtrées avant tri
🔎 Une clause Limit inefficace
Symptôme :
Pourquoi c’est un souci
PostgreSQL trie toute la table avant d’en extraire 10 lignes. S’il y a 1 million de lignes, c’est pas optimal.
Comment le voir
Le SORT est au-dessus du LIMIT
Le tri prend beaucoup de temps même pour un LIMIT 10
Solutions
Utiliser un index qui permet de lire déjà trié (ORDER BY created_at DESC → index DESC)
Repenser la requête pour éviter le tri global (ex : préfiltrage ou pagination efficace)
🔎 Des filtres appliqués trop tard
Symptôme :
Pourquoi c’est un souci
Le filtre est appliqué après avoir lu la majorité des lignes → PostgreSQL fait beaucoup de travail inutile.
Comment le voir
Présence de FILTER (…) en bas de plan
Très grand nombre de ROWS REMOVED BY FILTER
Solutions
Indexer la colonne du filtre
Réécrire la requête pour que le filtre soit pris en compte plus tôt dans le plan
Éviter les fonctions non indexables dans le WHERE (ex : LOWER(email) → préférer un index fonctionnel)
Conclusion
Comme souvent avec PostgreSQL, il est difficile — voire impossible — de tout couvrir en un seul article. Chaque plan d’exécution est unique, chaque requête a ses subtilités, et chaque base de données a ses petites surprises. Il n’existe pas de recette miracle qui marcherait à tous les coups.
Mais avec les bons réflexes, quelques outils et un peu de méthode, on peut rapidement progresser : repérer les symptômes, lire les signes, poser les bonnes questions… et surtout, tester, encore et toujours.
EXPLAIN ANALYZE n’est pas réservé aux DBA ou aux experts en perfs. C’est un compagnon de route pour toute personne qui écrit des requêtes, et qui veut comprendre ce qui se passe sous le capot.
Et si vous vous sentez encore un peu perdu·e face à un plan trop verbeux : pas de panique. Avec l’habitude, ça devient un langage qu’on apprend à lire presque instinctivement. Et ça commence maintenant.
Continuez votre lecture sur le blog :
- “Pruning” de partitions sous PostgreSQL ou comment bien élaguer ! (Capdata team) [PostgreSQL]
- PostgreSQL 13 : présentation (Emmanuel RAMI) [PostgreSQL]
- Nouveautés pg_stat_statements avec PostgreSQL 15 (David Baffaleuf) [PostgreSQL]
- PostgreSQL 18 : des IO asynchrones performantes ! (Emmanuel RAMI) [Non classéPostgreSQL]
- PostgreSQL : optimiser vos opérations vacuum et analyze ! (Emmanuel RAMI) [PostgreSQL]