
La gestion efficace des clusters PostgreSQL dans un environnement Kubernetes est un défi complexe auquel sont confrontées de nombreuses entreprises aujourd’hui. PGO offre une solution déclarative qui automatise la gestion des clusters PostgreSQL, simplifiant ainsi le déploiement, la mise à l’échelle et la gestion des bases de données PostgreSQL dans un environnement Kubernetes.
Pour faire suite à l’article de David sur PGO et à la demande d’un de nos clients, j’ai réalisé une étude approfondie de plusieurs fonctionnalités de PGO.
Cet article va faire un petit tour d’horizon des outils principaux inclus dans l’implémentation de PGO. Que ce soit pour la sauvegarde avec pgbackrest, pour la balance des connexion avec pgbouncer ou pour le monitoring avec prometheus, PGO ne manque pas d’utilitaire dont l’utilisation est facilitée par la solution tout embarqué.
Pgbackrest :
Utilité :
PgBackRest est une solution de sauvegarde et de restauration pour les bases de données PostgreSQL qui propose plusieurs fonctionnalités, telles que la sauvegarde et la restauration parallèles, la compression, les sauvegardes complètes, différentielles et incrémentielles, la rotation des sauvegardes et l’expiration des archives, l’intégrité des sauvegardes, etc. Il prend en charge plusieurs référentiels, qui peuvent être situés localement ou à distance via TLS/SSH, ou être des stockages fournis par le cloud comme S3/GCS/Azure.
L’architecture de pgbackrest pour PGO est la suivante :
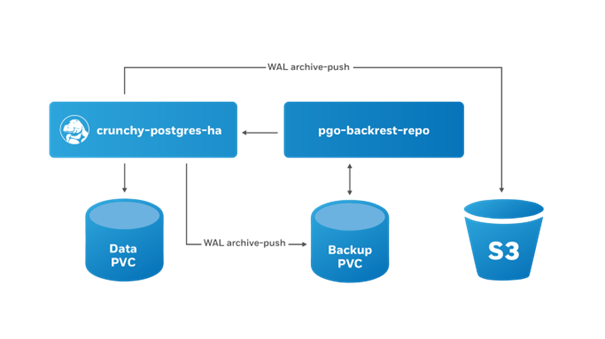
Mise en place :
On peut imaginer plusieurs moyens de mettre en place le pgbackrest. Dans un premier temps, nous avons la sauvegarde classique en système de fichier, comme dans notre exemple sur le blog :
1) La sauvegarde sur volume persistant Kubernetes :
- name: repo1
volume:
volumeClaimSpec:
accessModes:
- "ReadWriteOnce"
resources:
requests:
storage: 1Gi
Ce type de sauvegarde utilise un volume persistant de Kubernetes pour recueillir nos sauvegardes et les garder.
Une PersistentVolumeClaim (PVC) est une demande de stockage faite par un utilisateur. Elle est similaire à un Pod. Les Pods consomment des ressources de nœud et les PVC consomment des ressources de PV (PersistentVolume). Les Pods peuvent demander des niveaux spécifiques de ressources (CPU et mémoire). Les revendications peuvent demander une taille spécifique et des modes d’accès spécifiques (par exemple, elles peuvent être montées en ReadWriteOnce, ReadOnlyMany, ReadWriteMany, ou ReadWriteOncePod, voir AccessModes).
2) Le stockage pour S3 :
Pour pouvoir faire du stockage dans S3, il faut rajouter un fichier de configuration dans notre dossier de déploiement. Le fichier doit s’appeler s3.conf. Ce fichier contient les crédential de connexion à un AWS S3 :
repo1-s3-key=$YOUR_AWS_S3_KEY repo1-s3-key-secret=$YOUR_AWS_S3_KEY_SECRET
Une fois que c’est configuré dans votre fichier, il ne reste plus qu’à modifier le postgresql.yaml, et configurer dans la partie backup :
backups:
pgbackrest:
image: registry.developers.crunchydata.com/crunchydata/crunchy-pgbackrest:ubi8-2.49-0
configuration:
- secret:
name: pgo-s3-creds
global:
repo1-path: /pgbackrest/postgres-operator/pgcluster1/repo1
repos:
- name: repo1
s3:
bucket: "<YOUR_AWS_S3_BUCKET_NAME>"
endpoint: "<YOUR_AWS_S3_ENDPOINT>"
region: "<YOUR_AWS_S3_REGION>"
Une fois configuré, et le job mis dans le cron, vous devriez voir apparaitre les sauvegardes sur le volume S3.
3) Le stockage GCS :
Comme pour Amazon S3 on peut sauvegarder nos backups dans Google Cloud Storage. Pour pouvoir le faire fonctionner il vous faut copier votre GCS key secret (qui est un fichier JSON) dans un gcs.conf que vous allez placer dans votre dossier Kustomize.
Il vous suffit ensuite de modifier votre fichier postgres.yaml pour ajouter dans la partie backup la configuration pour une sauvegarde gcs :
backups:
pgbackrest:
image: registry.developers.crunchydata.com/crunchydata/crunchy-pgbackrest:ubi8-2.49-0
configuration:
- secret:
name: pgo-gcs-creds
global:
repo1-path: /pgbackrest/postgres-operator/pgcluster1/repo1
repos:
- name: repo1
gcs:
bucket: "<YOUR_GCS_BUCKET_NAME>"
Il ne vous reste plus qu’à regénérer vos pods, et votre sauvegarde arrivera directement dans votre Google Cloud Service.
4) Le stockage Azur Blob Storage :
Comme pour les deux points précédents, vous pouvez également stocker vos sauvegardes sur le blob storage d’Azure. Pour cela il vous faut créer un fichier dans votre kustomize, avec à l’intérieur la configuration pour votre point de sauvegarde Azure. Il vous faut l’appeler azure.conf et il devra contenir les lignes suivantes :
repo1-azure-account=$YOUR_AZURE_ACCOUNT repo1-azure-key=$YOUR_AZURE_KEY
Il faut ensuite intégrer ces modifications dans votre fichier postgres.yaml :
backups:
pgbackrest:
image: registry.developers.crunchydata.com/crunchydata/crunchy-pgbackrest:ubi8-2.49-0
configuration:
- secret:
name: pgo-azure-creds
global:
repo1-path: /pgbackrest/postgres-operator/pgcluster/repo1
repos:
- name: repo1
azure:
container: "<YOUR_AZURE_CONTAINER>"
Bien sur rien ne vous interdit, et c’est même conseillé, de joindre plusieurs moyens de sauvegarde. Cela permet notamment de s’assurer une plus grande fiabilité du système de sauvegarde, en s’assurant qu’elles sont disponibles à plusieurs endroits.
Une fois que vous avez décidé d’où vous allez stocker vos sauvegardes, et que vous l’avez configuré, il faut maintenant décider des différents paramètres de ces sauvegardes : la programmation, la rétention…
5) La programmation des sauvegardes :
Il faut savoir que par défaut, PGO sauvegarde automatiquement les WAL dans la méthode de sauvegarde que vous lui avez configuré. C’est donc une forme de sauvegarde en soit.
Mais dans le cadre d’une récupération après incident majeur, il peut aussi être utilise d’avoir des sauvegardes full programmées. Pgbackrest, qui est l’outil utilisé par PGO permet de mettre en place trois types de sauvegarde : les incrémentales, les différentielles et les fulls.
Chaque type de sauvegarde peut être programmée en suivant une notation identique à celle des crontab. Par exemple :
backups:
pgbackrest:
repos:
- name: repo1
schedules:
full: "0 1 * * 0"
differential: "0 1 * * 1-6"
Le fait d’implémenter ces planifications créera des CronJobs dans Kubernetes.
6) La rétention des backups :
Vous pouvez définir une rétention maximum pour vos backups sur le support de backup de votre choix. Une fois que cette rétention sera atteinte, pgbackrest fera le ménage tout seul des sauvegardes et des WAL qui lui sont reliées.
Il y a deux types de rétentions que l’on peut définir : les rétentions « count » basées sur le nombre de backup que l’on souhaite garder et les rétentions « time » basées sur le nombre de jours ou vous souhaitez garder votre sauvegarde.
backups:
pgbackrest:
global:
repo1-retention-full: "14"
repo1-retention-full-type: time
7) La sauvegarde unique :
Si dans le cadre d’un besoin particuliers, une grosse modification ou une migration par exemple, vous avez besoin de prendre une sauvegarde immédiate sans forcément attendre que le cron n’arrive, vous pouvez le faire.
Pour la configuration de cette sauvegarde, il faudra l’annoter comme « manuelle » :
backups:
pgbackrest:
manual:
repoName: repo1
options:
- --type=full
Il vous faudra ensuite déclencher cette sauvegarde avec une commande manuelle. Dans le cadre de notre cluster exemple pgcluster1 :
kubectl annotate -n postgres-operator postgrescluster pgcluster1 \ postgres-operator.crunchydata.com/pgbackrest-backup=”$(date)”
8) Faire un clone à partir d’un repo :
Quand on a configuré un repo sur notre instance primaire, on peut facilement créer un clone de notre instance à l’aide de notre sauvegarde. Ainsi, on créer un tout nouveau Pods à partir des informations stockées à propos du pod que l’on possède déjà. Ici, nous allons créer un nouveau pod à partir de notre pod pgcluster1 :
apiVersion: postgres-operator.crunchydata.com/v1beta1
kind: PostgresCluster
metadata:
name: pgcluster2
spec:
dataSource:
postgresCluster:
clusterName: pgcluster1
repoName: repo1
image: registry.developers.crunchydata.com/crunchydata/crunchy-postgres:ubi8-16.2-0
postgresVersion: 16
instances:
- dataVolumeClaimSpec:
accessModes:
- "ReadWriteOnce"
resources:
requests:
storage: 1Gi
backups:
pgbackrest:
image: registry.developers.crunchydata.com/crunchydata/crunchy-pgbackrest:ubi8-2.49-0
repos:
- name: repo1
volume:
volumeClaimSpec:
accessModes:
- "ReadWriteOnce"
resources:
requests:
storage: 1Gi
Ici on peut noter entre autres la partie spec de la configuration, qui est le morceau de yaml nous permettant de dire qu’on s’appuie sur le cluster existant pour créer un clone indépendant :
spec:
dataSource:
postgresCluster:
clusterName: pgcluster1
repoName: repo1
9) Point in Time Recovery :
De la même façon, si l’on veut faire une restauration PITR, nous allons remplir la balise spec de notre yaml. Attention cependant, pour faire une restauration PITR, nous avons besoin de posséder encore la sauvegarde. On ne peut pas faire une restauration PITR sur une sauvegarde lointaine qu’on ne possèderait plus. Imaginons que je souhaite repartir d’une sauvegarde datant d’hier soir à 20h30 de mon instance pgcluster1 sur mon instance pgcluster2, la configuration serait la suivante :
apiVersion: postgres-operator.crunchydata.com/v1beta1
kind: PostgresCluster
metadata:
name: pgcluster2
spec:
dataSource:
postgresCluster:
clusterName: pgcluster1
repoName: repo1
options:
- --type=time
- --target="2024-04-09 20:30:00-00"
image: registry.developers.crunchydata.com/crunchydata/crunchy-postgres:ubi8-16.2-0
postgresVersion: 16
instances:
- dataVolumeClaimSpec:
accessModes:
- "ReadWriteOnce"
resources:
requests:
storage: 1Gi
backups:
pgbackrest:
image: registry.developers.crunchydata.com/crunchydata/crunchy-pgbackrest:ubi8-2.49-0
repos:
- name: repo1
volume:
volumeClaimSpec:
accessModes:
- "ReadWriteOnce"
resources:
requests:
storage: 1Gi
La partie qui nous intéresse ici est la partie spec, ou nous avons rajouter un type de restauration (ici time) et une heure target. Cela indique à pgbackrest qu’il doit aller chercher tous les fichiers de sauvegarde et WAL sur notre point de sauvegarde repo1 venant de l’instance pgcluster1 pour les réappliquer sur notre nouveau cluster pgcluster2.
Vous pouvez également vouloir réaliser une restauration In Place, c’est-à-dire écraser l’instance présente pour la remplacer par la restauration. Auquel cas, plutôt que de préciser comment s’appellera notre nouveau cluster, il faut alors passer par la balise restore :
spec:
backups:
pgbackrest:
restore:
enabled: true
repoName: repo1
options:
- --type=time
- --target="2024-04-09 20:30:00-00"
Ici, comme précédemment, nous restaurons à l’heure de 20 :30 hier soir, et cela sur notre propre instance. Ne reste plus qu’à lancer la restauration :
kubectl annotate -n postgres-operator postgrescluster pgcluster1 --overwrite \ postgres-operator.crunchydata.com/pgbackrest-restore="$(date)"
A noter qu’il ne faut pas oublier de désactiver ensuite le restore en le passant à false si vous ne souhaitez pas qu’il soit de nouveau écrasé au prochain changement de configuration.
10) Restaurer une base de données spécifique :
Si votre besoin est de restaurer une base de données spécifique plutôt que l’intégralité de l’instance, vous pouvez le préciser dans les paramètres de votre restauration.
Attention cependant, ce n’est pas une restauration comme le serais un pg_dump. Ici si vous restaurez simplement une seule base de données et pas le reste du cluster, les autres bases que vous n’avez pas choisit de restaurer deviendront inaccessibles.
Si nous voulons restaurer une base de données, et uniquement elle, voici la procédure :
spec:
backups:
pgbackrest:
restore:
enabled: true
repoName: repo1
options:
- --db-include=capdata
Ici, on ne restaurera que la base de données capdata, et aucunes autres bases à partir de notre repo1.
PgBouncer :
Utilité :
PgBouncer est un pooler de connexion pour PostgreSQL. Un pooler de connexion permet de maintenir ouvertes des sessions entre lui-même et le serveur, ce qui rend plus rapide l’ouverture de sessions depuis les clients, une application Web par exemple.
PgBouncer permet aussi de mutualiser les sessions dans le serveur, économisant ainsi des ressources. PgBouncer propose plusieurs modes de partage : par requête (default), par transaction ou par session.
Mise en place :
Pour ajouter un bouncer à notre configuration c’est une réalité très simple. Il suffit d’ajouter dans notre fichier postgres.yaml la rubrique proxy :
proxy:
pgBouncer:
image: registry.developers.crunchydata.com/crunchydata/crunchy-pgbouncer:ubi8-1.21-3
Une fois que vous avez rajouté cela dans la configuration, il n’y a plus qu’à appliquer celle-ci :
kubectl apply -k kustomize/keycloak
Quand PGO créé un nouveau connexion pooler sur notre instance déployée, il modifier le fichier secrets de l’utilisateur.
On voit que plusieurs champs qui concerne pg_bouncer sont apparus. Ils constituent les informations qui vont vous permettre de vous connecter sur votre bouncer nouvellement créé :
{
"apiVersion": "v1",
"data": {
"dbname": "cGdjbHVzdGVyMQ==",
"host": "cGdjbHVzdGVyMS1wcmltYXJ5LnBvc3RncmVzLW9wZXJhdG9yLnN2Yw==",
"jdbc-uri": "amRiYzpwb3N0Z3Jlc3FsOi8vcGdjbHVzdGVyMS1wcmltYXJ5LnBvc3RncmVzLW9wZXJhdG9yLnN2Yzo1NDMyL3BnY2x1c3RlcjE/cGFzc3dvcmQ9NXNSaSUzRCU1QmZZbSUzQ2lSSGslMkElNUIlM0VuWGhqaiU3Q1EmdXNlcj1wZ2NsdXN0ZXIx",
"password": "NXNSaT1bZlltPGlSSGsqWz5uWGhqanxR",
"pgbouncer-host": "cGdjbHVzdGVyMS1wZ2JvdW5jZXIucG9zdGdyZXMtb3BlcmF0b3Iuc3Zj",
"pgbouncer-jdbc-uri": "amRiYzpwb3N0Z3Jlc3FsOi8vcGdjbHVzdGVyMS1wZ2JvdW5jZXIucG9zdGdyZXMtb3BlcmF0b3Iuc3ZjOjU0MzIvcGdjbHVzdGVyMT9wYXNzd29yZD01c1JpJTNEJTVCZlltJTNDaVJIayUyQSU1QiUzRW5YaGpqJTdDUSZwcmVwYXJlVGhyZXNob2xkPTAmdXNlcj1wZ2NsdXN0ZXIx",
"pgbouncer-port": "NTQzMg==",
"pgbouncer-uri": "cG9zdGdyZXNxbDovL3BnY2x1c3RlcjE6NXNSaT0lNUJmWW0lM0NpUkhrJTJBJTVCJTNFblhoamolN0NRQHBnY2x1c3RlcjEtcGdib3VuY2VyLnBvc3RncmVzLW9wZXJhdG9yLnN2Yzo1NDMyL3BnY2x1c3RlcjE=",
"port": "NTQzMg==",
"uri": "cG9zdGdyZXNxbDovL3BnY2x1c3RlcjE6NXNSaT0lNUJmWW0lM0NpUkhrJTJBJTVCJTNFblhoamolN0NRQHBnY2x1c3RlcjEtcHJpbWFyeS5wb3N0Z3Jlcy1vcGVyYXRvci5zdmM6NTQzMi9wZ2NsdXN0ZXIx",
"user": "cGdjbHVzdGVyMQ==",
"verifier": "U0NSQU0tU0hBLTI1NiQ0MDk2OlgyQ3NQRU1FZjh3QkVlc05McDFJTkE9PSRKcDhKakl5Q0o1ZEpFRVhia1ptUERTNE5rR3d0V00rczdrMElsQmx0YkpvPTpEaHg3VzNCOE5vNDRYSHJ1Qm1RdENMQW9jNEtnSUZQa2dIeStUMkVWUUowPQ=="
},
"kind": "Secret",
"metadata": {
"creationTimestamp": "2024-04-09T16:37:36Z",
"labels": {
"postgres-operator.crunchydata.com/cluster": "pgcluster1",
"postgres-operator.crunchydata.com/pguser": "pgcluster1",
"postgres-operator.crunchydata.com/role": "pguser"
},
"name": "pgcluster1-pguser-pgcluster1",
"namespace": "postgres-operator",
"ownerReferences": [
{
"apiVersion": "postgres-operator.crunchydata.com/v1beta1",
"blockOwnerDeletion": true,
"controller": true,
"kind": "PostgresCluster",
"name": "pgcluster1",
"uid": "7260b882-116f-4b02-b51a-18d4fe3a8038"
}
],
"resourceVersion": "9495",
"uid": "1fbdf1d2-48ea-4a45-b7d6-01248317dbee"
},
"type": "Opaque"
}
Pour se connecter à notre pgbouncer, il suffit d’utiliser les informations fournies par le fichier de secret à la place de nos infos de connexion habituelles, et cela nous permet d’accéder directement au bouncer et non plus à l’instance elle-même.
Cette connexion peut être facilement modifiée en utilisant la documentation de pgbouncer afin de pouvoir configurer à notre guise notre pgbouncer. Un exemple de configuration qu’on pourrais rencontrer serait :
proxy:
pgBouncer:
image: {{.Values.image.pgBouncer }}
config:
global:
default_pool_size: "100"
max_client_conn: "10000"
pool_mode: transaction
Pour cet exemple on voit qu’on a définit un nombre de client maximum, la taille du pool à 100 et un mode transaction pour notre pool.
PGO et Prometheus
Utilité :
Prometheus est une trousse à outils de surveillance et d’alerte des systèmes en open source.
Prometheus collecte et stocke ses métriques sous forme de données de séries temporelles, c’est-à-dire que les informations de métriques sont stockées avec le timestamp auquel elles ont été enregistrées, aux côtés de paires clé-valeur optionnelles appelées labels.
– Un modèle de données multidimensionnel avec des données de séries temporelles identifiées par le nom de la métrique et des paires clé-valeur
– PromQL, un langage de requête flexible pour exploiter cette dimensionnalité
– Aucune dépendance sur le stockage distribué ; les nœuds de serveur individuels sont autonomes
– La collecte de séries temporelles se fait via un modèle de tirage sur HTTP
– La poussée de séries temporelles est prise en charge via une passerelle intermédiaire
– Les cibles sont découvertes via la découverte de service ou la configuration statique
– Prise en charge de plusieurs modes de graphiques et de tableaux de bord
Mise en place :
Pour pouvoir mettre en place une surveillance pour notre cluster, il est plus simple de télécharger et compléter le modèle fournit dans les exemples de pgo.
Ainsi, on peut récupérer les exemples à l’aide de git :
YOUR_GITHUB_UN="$YOUR_GITHUB_USERNAME"
git clone --depth 1 "git@github.com:${YOUR_GITHUB_UN}/postgres-operator-examples.git"
cd postgres-operator-examples
Les différentes configurations se trouvent dans le dossier kustomize/monitoring.
Pour activer le monitoring de notre instance, il faut ajouter la balise monitoring à notre fichier postgres.yaml :
monitoring:
pgmonitor:
exporter:
image: registry.developers.crunchydata.com/crunchydata/crunchy-postgres-exporter:ubi8-5.5.1-0
Une fois notre configuration modifiée, on l’applique afin que PGO détecte les changements et configure tout seul l’exporter pour qu’il puisse se connecter à nos bases de données et récupérer les métriques.
kubectl apply -k kustomize/postgres
Il faut ensuite appliquer la configuration de base de pgmonitor pour qu’il créé lui-même les fichiers de configuration pour prometheus (il le fera en même temps pour Grafana et Alertmanager qui sont deux autres outils de surveillance). Pour cela on applique le kustomize présent dans le dossier monitoring :
$kubectl apply -k kustomize\postgres postgrescluster.postgres-operator.crunchydata.com/pgcluster1 configured $kubectl apply -k kustomize\monitoring serviceaccount/alertmanager created serviceaccount/grafana created serviceaccount/prometheus created clusterrole.rbac.authorization.k8s.io/prometheus created clusterrolebinding.rbac.authorization.k8s.io/prometheus created configmap/alert-rules-config created configmap/alertmanager-config created configmap/crunchy-prometheus created configmap/grafana-dashboards created configmap/grafana-datasources created secret/grafana-admin created service/crunchy-alertmanager created service/crunchy-grafana created service/crunchy-prometheus created persistentvolumeclaim/alertmanagerdata created persistentvolumeclaim/grafanadata created persistentvolumeclaim/prometheusdata created deployment.apps/crunchy-alertmanager created deployment.apps/crunchy-grafana created deployment.apps/crunchy-prometheus created
Nos services ont été correctement déployés, il ne nous reste plus qu’à utiliser celui qui nous intéresse, ici service/crunchy-prometheus et lui indiquer de commencer à envoyer les informations sur notre prometheus :
$kubectl -n postgres-operator port-forward service/crunchy-prometheus 9090:9090 Forwarding from 127.0.0.1:9090 -> 9090 Forwarding from [::1]:9090 -> 9090 Handling connection for 9090 Handling connection for 9090
Afin d’accéder à notre service prometheus, il ne nous reste plus qu’à se connecter avec l’adresse de notre machine, sur le port 9090 préalablement ouvert, pour voir apparaitre le dashboard de prometheus :
PGO Client :
Utilité :
Pour pouvoir gérer plus facilement le cluster créé par PGO, CrunchyData à développé une surcouche à kubectl qui permet de faciliter les commandes que nous pouvons réaliser sur le cluster.
Cela permet de ne pas avoir à taper les longues lignes de commandes qui permettent par exemple de démarrer les sauvegardes unitaires.
Mise en place :
Pour pouvoir installer cette surcouche, il faut télécharger la version qui correspond au système d’exploitation à partir du GIT de pgo client :
# wget https://github.com/CrunchyData/postgres-operator-client/releases/download/v0.4.1/kubectl-pgo-linux-arm64 --2024-04-11 12:07:45-- https://github.com/CrunchyData/postgres-operator-client/releases/download/v0.4.1/kubectl-pgo-linux-arm64 Resolving github.com (github.com)... 140.82.121.4 Connecting to github.com (github.com)|140.82.121.4|:443... connected. HTTP request sent, awaiting response... 302 Found Resolving objects.githubusercontent.com (objects.githubusercontent.com)... 185.199.109.133, 185.199.111.133, 185.199.110.133, ... Connecting to objects.githubusercontent.com (objects.githubusercontent.com)|185.199.109.133|:443... connected. HTTP request sent, awaiting response... 200 OK Length: 47895849 (46M) [application/octet-stream] Saving to: ‘kubectl-pgo-linux-arm64’ kubectl-pgo-linux-arm64 100%[========================================================================================================================================>] 45.68M --.-KB/s in 0.1s 2024-04-11 12:07:45 (373 MB/s) - ‘kubectl-pgo-linux-arm64’ saved [47895849/47895849]
On renome le fichier téléchargé en kubectl-pgo et on le déplace dans nos bin pour pouvoir les utiliser :
# mv kubectl-pgo-linux-arm64 kubectl-pgo # sudo mv kubectl-pgo /usr/local/bin/kubectl-pgo # sudo chmod +x /usr/local/bin/kubectl-pgo Une fois que ces actions sont réalisées, on peut tester le fonctionnement : # kubectl pgo version Client Version: v0.4.1 Operator Version: v5.5.1
Les commandes disponibles avec cette extension sont les suivantes :
– backup : Backup cluster
– create : Create a resource
– delete : Delete a resource
– help : Help about any command
– restore : Restore cluster
– show Show : PostgresCluster details
– start : Start cluster
– stop : Stop cluster
– support : Crunchy Support commands for PGO
– version : PGO client
Continuez votre lecture sur le blog :
- PGO : opérateurs kubernetes pour PostgreSQL, la suite ! (David Baffaleuf) [ContainerDevopsPostgreSQL]
- Kubegres : l’opérateur Kubernetes clé en main pour PostgreSQL (David Baffaleuf) [ContainerDevopsPostgreSQL]
- PostgreSQL : Comparatif entre Barman et pgBackRest (Capdata team) [PostgreSQL]
- PostgreSQL sur la solution Kubernetes locale Minikube (Emmanuel RAMI) [ContainerPostgreSQL]
- Sauvegardes SQL Server dans un Azure Blob Storage (Capdata team) [AzureSQL Server]