
Salut à toutes et tous ! Cette semaine la suite de notre petit tour des opérateurs Kubernetes pour PostgreSQL, et après kubegres, c’est au tour de PGO de CrunchyData.

Quelques infos générales sur l’opérateur PGO
Comparé à Kubegres, PGO semble plus complet dans le sens où il intègre de base un réplica par défaut, mais aussi la possibilité de backuper directement avec pgBackRest dans des repositories locaux ou cloud, un pod pgBouncer, et un exporter pour Prometheus.
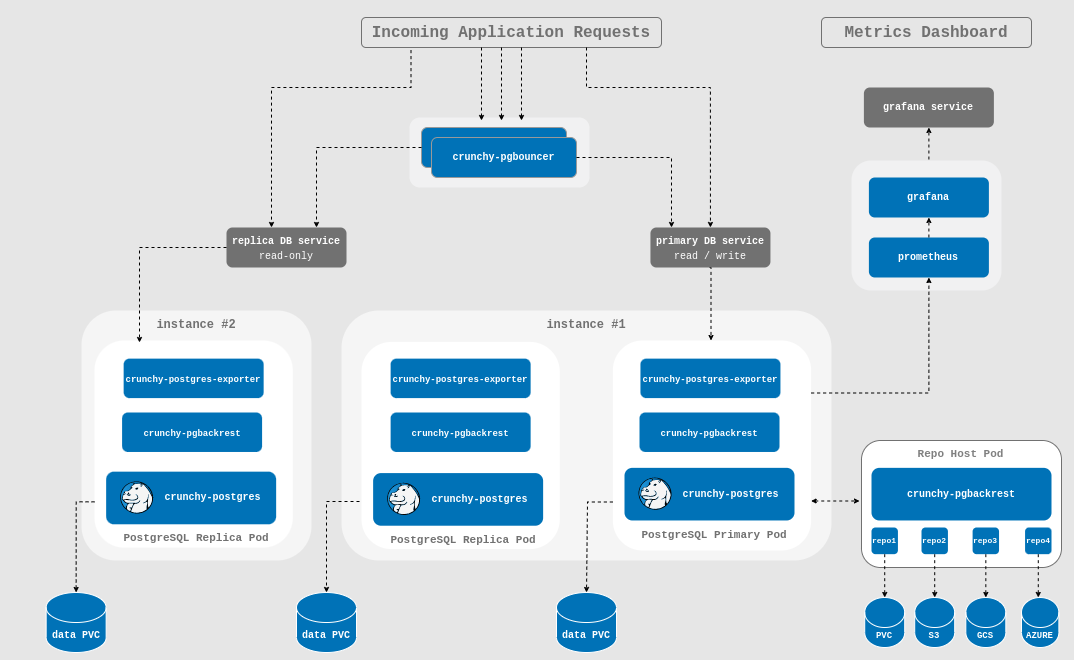
Comme pour kubegres, l’operateur PGO encapsule à l’intérieur de ses deployments des objets de base Kubernetes tels que des StatefulSets pour les pods primaire et replicas, des Services, des PV et PVC pour le stockage, etc… comme nous allons le voir lors du deploiement de notre premier cluster.
Installation de l’opérateur PGO
Première chose à faire avant de créer notre premier cluster, déployer l’opérateur PGO. Il est possible de le faire au choix soit via Kustomize soit via Helm. CrunchyData propose un repo git à cloner et qui contient déjà les fichiers de configuration de base, que nous pourrons modifier au besoin pour customiser notre déploiement. Une fois le git cloné sur notre github Capdata, nous pouvons commencer à récupérer les fichiers en local et regarder le contenu des fichiers de définition. Nous utiliserons Kustomize pour l’exemple :
$ git clone --depth=1 "https://github.com/Capdata/postgres-operator-examples.git" Cloning into 'postgres-operator-examples'... remote: Enumerating objects: 140, done. remote: Counting objects: 100% (140/140), done. remote: Compressing objects: 100% (105/105), done. remote: Total 140 (delta 33), reused 81 (delta 26), pack-reused 0 Receiving objects: 100% (140/140), 150.57 KiB | 3.01 MiB/s, done. Resolving deltas: 100% (33/33), done. $ cd postgres-operator-examples/kustomize $ tree -a install/namespace/ install/namespace/ ├── kustomization.yaml └── namespace.yaml $ tree -a install/default/ install/default/ ├── kustomization.yaml └── selectors.yaml
L’apply de ~kustomize/install/namespace/namespace.yaml va créer un namespace dédié postgres-operator:
apiVersion: v1 kind: Namespace metadata: name: postgres-operator
Puis ~kustomize/install/default va créer le reste de l’opérateur:
$ kubectl apply --kustomize=kustomize/install/namespace namespace/postgres-operator created $ kubectl apply --server-side --kustomize=kustomize/install/default customresourcedefinition.apiextensions.k8s.io/pgupgrades.postgres-operator.crunchydata.com serverside-applied customresourcedefinition.apiextensions.k8s.io/postgresclusters.postgres-operator.crunchydata.com serverside-applied serviceaccount/pgo serverside-applied serviceaccount/postgres-operator-upgrade serverside-applied clusterrole.rbac.authorization.k8s.io/postgres-operator serverside-applied clusterrole.rbac.authorization.k8s.io/postgres-operator-upgrade serverside-applied clusterrolebinding.rbac.authorization.k8s.io/postgres-operator serverside-applied clusterrolebinding.rbac.authorization.k8s.io/postgres-operator-upgrade serverside-applied deployment.apps/pgo serverside-applied deployment.apps/pgo-upgrade serverside-applied $ kubectl get all --namespace=postgres-operator NAME READY STATUS RESTARTS AGE pod/pgo-774db98dbc-htm5d 1/1 Running 0 74m pod/pgo-upgrade-785dd6dc4c-cw2ld 1/1 Running 0 74m NAME READY UP-TO-DATE AVAILABLE AGE deployment.apps/pgo 1/1 1 1 74m deployment.apps/pgo-upgrade 1/1 1 1 74m NAME DESIRED CURRENT READY AGE replicaset.apps/pgo-774db98dbc 1 1 1 74m replicaset.apps/pgo-upgrade-785dd6dc4c 1 1 1 74m
Création d’un premier cluster PGO
Maintenant que notre opérateur est installé, c’est le moment de s’intéresser au paramétrage du futur cluster. Tout se trouve dans ~kustomize/postgres:
$ tree -a postgres/ postgres/ ├── kustomization.yaml └── postgres.yaml
Le coeur de notre cluster se trouve dans postgresl.yaml :
apiVersion: postgres-operator.crunchydata.com/v1beta1
kind: PostgresCluster
metadata:
name: hippo
spec:
image: registry.developers.crunchydata.com/crunchydata/crunchy-postgres:ubi8-15.2-0
postgresVersion: 15
instances:
- name: instance1
dataVolumeClaimSpec:
accessModes:
- "ReadWriteOnce"
resources:
requests:
storage: 1Gi
backups:
pgbackrest:
image: registry.developers.crunchydata.com/crunchydata/crunchy-pgbackrest:ubi8-2.41-4
repos:
- name: repo1
volume:
volumeClaimSpec:
accessModes:
- "ReadWriteOnce"
resources:
requests:
storage: 1Gi
Comme pour Kubegres, l’opérateur PGO nous permet de créer un nouveau type d’objet dans Kubernetes :
kind: PostgresCluster
Le nom du cluster par défaut est ‘hippo‘ mais nous pourrons le changer sans problème. Pour les pods (primaire, réplicas, pgBackRest), les images sont précisées ainsi que les volumes qui sont rattachés via des abstractions de PVC appelées soit “dataVolumeClaimSpec” pour les pods PostgreSQL soit “VolumeClaimSpec” pour la partie sauvegarde.
Nous pouvons compléter le fichier de définition par défaut avec quelques customisations:
– Ajouter des quotas de ressources CPU et mémoire via instances.resources.limits
– Ajouter un réplica
– Renommer notre cluster ‘pgcluster1‘
– Et enfin ajouter un nodePort pour exposer notre cluster au monde extérieur :
apiVersion: postgres-operator.crunchydata.com/v1beta1
kind: PostgresCluster
metadata:
name: pgcluster1
spec:
image: registry.developers.crunchydata.com/crunchydata/crunchy-postgres:ubi8-15.2-0
postgresVersion: 15
instances:
- name: postgresdb1
replicas: 2
resources:
limits:
cpu: "0.5"
memory: 1Gi
dataVolumeClaimSpec:
accessModes:
- "ReadWriteOnce"
resources:
requests:
storage: 1Gi
backups:
pgbackrest:
image: registry.developers.crunchydata.com/crunchydata/crunchy-pgbackrest:ubi8-2.41-4
repos:
- name: repo1
volume:
volumeClaimSpec:
accessModes:
- "ReadWriteOnce"
resources:
requests:
storage: 1Gi
service:
metadata:
annotations:
annotation1: "mdnodeport1"
labels:
label1: "32000"
type: NodePort
nodePort: 32000
Pour la configuration des sauvegardes, nous verrons un peu plus tard. Dans l’immédiat, créons notre cluster:
$ kubectl apply -k kustomize/postgres/ postgrescluster.postgres-operator.crunchydata.com/pgcluster1 created $ kubectl get all --namespace=postgres-operator NAME READY STATUS RESTARTS AGE pod/pgcluster1-postgresdb1-55pl-0 4/4 Running 0 11s pod/pgcluster1-postgresdb1-9w2w-0 4/4 Running 0 11s pod/pgcluster1-repo-host-0 2/2 Running 0 11s pod/pgo-774db98dbc-tshp6 1/1 Running 0 68s pod/pgo-upgrade-785dd6dc4c-ntwkd 1/1 Running 0 68s NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE service/pgcluster1-ha NodePort 10.102.232.74 <none> 5432:32000/TCP 51m service/pgcluster1-ha-config ClusterIP None <none> <none> 51m service/pgcluster1-pods ClusterIP None <none> <none> 51m service/pgcluster1-primary ClusterIP None <none> 5432/TCP 51m service/pgcluster1-replicas ClusterIP 10.106.148.50 <none> 5432/TCP 51m NAME READY UP-TO-DATE AVAILABLE AGE deployment.apps/pgo 1/1 1 1 69s deployment.apps/pgo-upgrade 1/1 1 1 68s NAME DESIRED CURRENT READY AGE replicaset.apps/pgo-774db98dbc 1 1 1 68s replicaset.apps/pgo-upgrade-785dd6dc4c 1 1 1 68s NAME READY AGE statefulset.apps/pgcluster1-postgresdb1-55pl 1/1 11s statefulset.apps/pgcluster1-postgresdb1-9w2w 1/1 11s statefulset.apps/pgcluster1-repo-host 1/1 11s
Il se peut qu’il y ait des problèmes de quota mémoire / CPU disponible, les pods vont rester en Pending, et la suppression / recréation des objets ne suffit pas. La suppression du namespace se bloque en Terminating il a fallu que je déroule la procédure de suppression du namespace à la main pour repartir de zéro.
Bref notre déploiement nous a donc créé 3 nouveaux pods et 3 StatefulSets (primaire, réplica et pgBackRest), 4 services ClusterIP et notre nodePort.
Pour nous y connecter, nous avons besoin de récupérer le secret qui a été créé à l’initialisation du cluster. Jetons un coup d’oeil au secret dans sa globalité pour voir ce qu’il contient:
$ kubectl get secret --namespace=postgres-operator pgcluster1-pguser-pgcluster1 -o json
{
"apiVersion": "v1",
"data": {
"dbname": "cGdjbHVzdGVyMQ==",
"host": "cGdjbHVzdGVyMS1wcmltYXJ5LnBvc3RncmVzLW9wZXJhdG9yLnN2Yw==",
"jdbc-uri": "amRiYzpwb3N0Z3Jlc3FsOi8vcGdjbHVzdGVyMS1wcmltYXJ5LnBvc3RncmVzLW9wZXJhdG9yLnN2Yzo1NDMyL3BnY2x1c3RlcjE/cGFzc3dvcmQ9UHBybiUzQnZ1WDlrSiU1RE1WQnZwd3QzTk5wJTJBJnVzZXI9cGdjbHVzdGVyMQ==",
"password": "UHBybjt2dVg5a0pdTVZCdnB3dDNOTnAq",
"port": "NTQzMg==",
"uri": "cG9zdGdyZXNxbDovL3BnY2x1c3RlcjE6UHBybjt2dVg5a0olNURNVkJ2cHd0M05OcCUyQUBwZ2NsdXN0ZXIxLXByaW1hcnkucG9zdGdyZXMtb3BlcmF0b3Iuc3ZjOjU0MzIvcGdjbHVzdGVyMQ==",
"user": "cGdjbHVzdGVyMQ==",
"verifier": "U0NSQU0tU0hBLTI1NiQ0MDk2Olo3OTNBUVIwU0xZUVBDY3BXNkRaSXc9PSRWUWdlc0VlSGVvVnpnakc4emkyRGJJNmlpemo1ZnJGWmN2K3c3NzZScVhVPTpDT1JDVStoQU1IeDBkRzBKaGU3dllwUTdFWTB4QzZ5RzJUUE5NWFV5MTlRPQ=="
},
"kind": "Secret",
"metadata": {
"creationTimestamp": "2023-06-05T11:39:32Z",
"labels": {
"postgres-operator.crunchydata.com/cluster": "pgcluster1",
"postgres-operator.crunchydata.com/pguser": "pgcluster1",
"postgres-operator.crunchydata.com/role": "pguser"
},
"name": "pgcluster1-pguser-pgcluster1",
"namespace": "postgres-operator",
"ownerReferences": [
{
"apiVersion": "postgres-operator.crunchydata.com/v1beta1",
"blockOwnerDeletion": true,
"controller": true,
"kind": "PostgresCluster",
"name": "pgcluster1",
"uid": "80bbee62-0602-4012-9c06-dcd23ca7723b"
}
],
"resourceVersion": "169451",
"uid": "fe833c97-0585-4910-95ca-fb1c7774d5b2"
},
"type": "Opaque"
}
On a donc la possibilité de récupérer le user et le mot de passe :
$ export PGUSER=$(kubectl get secret --namespace=postgres-operator pgcluster1-pguser-pgcluster1 -o jsonpath={.data.user} | base64 -d)
$ export PGPASSWORD=$(kubectl get secret --namespace=postgres-operator pgcluster1-pguser-pgcluster1 -o jsonpath={.data.password} | base64 -d)
Et tester la connexion (noter que l’adresse IP est celle du node, ie kubectl describe nodes):
$ psql -h 192.168.59.101 -p 32000 -c "select version();"
version
---------------------------------------------------------------------------------------------------------
PostgreSQL 15.2 on x86_64-pc-linux-gnu, compiled by gcc (GCC) 8.5.0 20210514 (Red Hat 8.5.0-16), 64-bit
(1 row)
Bascules et haute disponibilité
Lançons une connexion en boucle sur le nodePort pour récupérer l’IP de l’instance primaire et voir ce qui se passe en cas de bascule.
$ while(true); do psql -h 192.168.59.101 -p 32000 -c "select inet_server_addr();"; sleep 1; done inet_server_addr ------------------ 172.17.0.7 (1 row) inet_server_addr ------------------ 172.17.0.7 (1 row) (...)
Pour tester la bascule, nous allons carrément supprimer le StatefulSet de l’instance primaire, il faut commencer par récupérer son nom, puis on supprime :
$ kubectl -n postgres-operator get pods \
--selector=postgres-operator.crunchydata.com/role=master \
-o jsonpath='{.items[*].metadata.labels.postgres-operator\.crunchydata\.com/instance}'
pgcluster1-postgresdb1-9w2w
$ kubectl delete statefulset --namespace=postgres-operator pgcluster1-postgresdb1-9w2w
statefulset.apps "pgcluster1-postgresdb1-9w2w" deleted
La connexion en boucle indique que l’on a bien changé d’IP:
(...) inet_server_addr ------------------ 172.17.0.7 (1 row) inet_server_addr ------------------ 172.17.0.7 (1 row) inet_server_addr ------------------ 172.17.0.6 (1 row) inet_server_addr ------------------ 172.17.0.6 (1 row)
… et minikube a détecté la perte du StatefulSet pgcluster1-postgresdb1-9w2w et l’a recréé en arrière plan:
$ kubectl get statefulset --namespace=postgres-operator NAME READY AGE pgcluster1-postgresdb1-55pl 1/1 96m pgcluster1-postgresdb1-9w2w 1/1 11s pgcluster1-repo-host 1/1 96m
Il existe un certain nombre d’options complémentaires notamment de l’anti-affinité pour éviter que les pods ne tournent sur les mêmes nodes, voir la documentation pour plus de détails.
Mise en place des backups via pgbackrest
Bien qu’il soit possible de sauvegarder directement sur AWS S3, Azure ou GCP, pour l’exemple nous avons déployé un volume Kubernetes simple.
Pour ajouter une planification et une rétention il faut rajouter quelques propriétés à spec.backups.pgbackrest :
backups:
pgbackrest:
image: registry.developers.crunchydata.com/crunchydata/crunchy-pgbackrest:ubi8-2.41-4
global:
repo1-retention-full: "14"
repo1-retention-full-type: time
repos:
- name: repo1
volume:
volumeClaimSpec:
accessModes:
- "ReadWriteOnce"
resources:
requests:
storage: 1Gi
schedules:
full: "50 15 * * *"
$ kubectl apply -k kustomize/postgres/ postgrescluster.postgres-operator.crunchydata.com/pgcluster1 configured $ kubectl get cronjobs --namespace=postgres-operator NAME SCHEDULE SUSPEND ACTIVE LAST SCHEDULE AGE pgcluster1-repo1-full 50 15 * * * False 0 <none> 106s
Kubernetes a créé un cronjob associé. Sachant que les backups peuvent être aussi différentiels ou incrémentaux selon la stratégie de sauvegarde envisagée.
La rétention quant à elle peut être indiquée en jours (time) ou en nombre de sauvegardes (count). Grâce à pgBackRest, PGO permettra ensuite d’utiliser les backups pour soit cloner les bases vers une autre cluster, soit le restaurer à un point dans le temps vers un nouveau cluster (pour comparer les données ou récupérer des lignes supprimées par erreur par exemple), ou restaurer in-place. Le sujet est assez long et cela pourra faire l’objet d’un futur épisode, mais globalement la puissance de feu de pgBackRest au service de la restaurabilité donne un atout supplémentaire à PGO par rapport à ses concurrents.
Conclusion
Dans cette première approche de PGO, nous n’avons fait qu’effleurer la surface des possibilités de cet opérateur, qui semble aller plus loin que ses concurrents avec:
– La sauvegarde et restauration via pgBackRest intégré, et la possibilité de sauvegarder directement dans le cloud.
– Intégration avec Promotheus.
– Intégration avec pgBouncer.
– Déployable directement via des standards tels que Kustomize ou Helm.
– Gestion des secrets intégrée.
etc… Sûrement que d’autres articles pour approfondir PGO viendront compléter celui-ci, en attendant bonne lecture et à bientôt sur le blog Cap Data !
Continuez votre lecture sur le blog :
- Kubegres : l’opérateur Kubernetes clé en main pour PostgreSQL (David Baffaleuf) [ContainerDevopsPostgreSQL]
- PGO : la suite (Sarah FAVEERE) [PostgreSQL]
- PostgreSQL sur la solution Kubernetes locale Minikube (Emmanuel RAMI) [ContainerPostgreSQL]
- Comparatif des gestionnaires de VIP dans un cluster Patroni : épisode 2 (VIP-MANAGER) (David Baffaleuf) [ContainerPostgreSQL]
- PostgreSQL : Comparatif entre Barman et pgBackRest (Capdata team) [PostgreSQL]