
I] Introduction:
Jusqu’à maintenant afin de pouvoir profiter des avantages du cloud AWS pour externaliser ses sauvegardes SQL Server, il fallait les réaliser de manière classique sur site (on premise) puis via un deuxième process les uploader dans un compartiment (bucket) S3.
Ceci rendait la tâche plus lourde à superviser et également impliquait d’avoir suffisamment d’espace de stockage sur site avant de pouvoir basculer nos fichiers de sauvegarde dans le nuage AWS.
L’une des nouveautés de SQLServer 2022 est la possibilité d’effectuer ses sauvegardes directement sur un bucket S3 en transact SQL via la commande classique “BACKUP DATABASE testbdd TO URL” .
II] Prérequis:
- Il faut disposer d’un compte ayant des droits d’administration sur votre environnement AWS au niveau des briques S3 et IAM:
Dans le cadre de cet article nous utiliserons AWS CLI en v2 pour créer nos ressources que l’on peut récupérer ici: https://aws.amazon.com/fr/cli/# Vérification de la version installée C:\Users\lprou>aws --version aws-cli/2.7.13 Python/3.9.11 Windows/10 exe/AMD64 prompt/off # Configuration via une clef d'accès d'un compte administrateur. C:\Users\lprou>aws configure AWS Access Key ID [None]: ****************HPWZ AWS Secret Access Key [None]: ****************Nx67 Default region name [None]: eu-west-3 Default output format [None]: json
Bien entendu il est tout à fait possible d’utiliser la console Web…
- Un bucket S3 devra être créé/configuré au préalable pour héberger nos fichiers de sauvegarde.
cf https://aws.amazon.com/fr/s3/
Pour ce genre d’utilisation il faut veiller à “Bloquer tous les accès publics”, activer ou non le chiffrement, les versions et le verrouillage d’objets… Pour rappel les coûts varient légèrement en fonction de la région choisi.# Consultation de l'aide de la commande create-bucket C:\Users\lprou>aws s3api create-bucket help # Création du compartiment S3 C:\Users\lprou>aws s3api create-bucket --bucket capdata-backupsqlserver --region eu-west-3 --create-bucket-configuration LocationConstraint=eu-west-3 --acl private --object-lock-enabled-for-bucket { "Location": "http://capdata-backupsqlserver.s3.amazonaws.com/" } # Désactivation de l'accès publique C:\Users\lprou>aws s3api put-public-access-block --bucket capdata-backupsqlserver --public-access-block-configuration "BlockPublicAcls=true,IgnorePublicAcls=true,BlockPublicPolicy=true,RestrictPublicBuckets=true" # Activation du chiffrage aws s3api put-bucket-encryption --bucket capdata-backupsqlserver --server-side-encryption-configuration "{\"Rules\": [{\"ApplyServerSideEncryptionByDefault\":{\"SSEAlgorithm\": \"AES256\"}}]}" - Un utilisateur IAM possédant une clé d’accès composée d’une “Access Key ID” ainsi que d’une “Secret Key ID” devra être créé.
Cet utilisateur devra avoir des droits d’écriture sur le bucket S3 concerné.
Ces identifiants seront utilisés par le moteur SQLServer pour s’authentifier au niveau du point de terminaison (endpoint) S3.
Ainsi pour des raisons évidentes de sécurité il est important de n’accorder que les droits minimums à cet utilisateur:# Création d'un utilisateur IAM C:\Users\lprou>aws iam create-user --user-name monSQLServer2022 { "User": { "Path": "/", "UserName": "monSQLServer2022", "UserId": "AIDAQIMXBNKBJZPXAIG4Z", "Arn": "arn:aws:iam::018033XXXXXX:user/monSQLServer2022", "CreateDate": "2022-07-08T09:42:56+00:00" } }# Création d'une clef d'accès pour l'utilisateur "monSQLServer2022" C:\Users\lprou>aws iam create-access-key --user-name monSQLServer2022 { "AccessKey": { "UserName": "monSQLServer2022", "AccessKeyId": "AKIAQIMXBNKBG4BLUJUP", "Status": "Active", "SecretAccessKey": "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", "CreateDate": "2022-07-08T10:01:26+00:00" } }# Création d'un fichier .json contenant la stratégie. Sauvegarder cet exemple de stratégie dans une fichier S3_monSQLServer2022.json { "Version": "2012-10-17", "Statement": [ { "Sid": "VisualEditor0", "Effect": "Allow", "Action": "s3:ListBucket", "Resource": "arn:aws:s3:::capdata-backupsqlserver" }, { "Sid": "VisualEditor1", "Effect": "Allow", "Action": "s3:ListAllMyBuckets", "Resource": "*" }, { "Sid": "VisualEditor2", "Effect": "Allow", "Action": [ "s3:PutObject", "s3:GetObject" ], "Resource": "arn:aws:s3:::capdata-backupsqlserver/*" } ] }# Création d'une stratégie C:\Users\lprou>aws iam create-policy --policy-name S3_monSQLServer2022 --policy-document file://C:\Users\lprou\S3_monSQLServer2022.json { "Policy": { "PolicyName": "S3_monSQLServer2022", "PolicyId": "ANPAQIMXBNKBLWEV7ZWBQ", "Arn": "arn:aws:iam::018033XXXXXX:policy/S3_monSQLServer2022", "Path": "/", "DefaultVersionId": "v1", "AttachmentCount": 0, "PermissionsBoundaryUsageCount": 0, "IsAttachable": true, "CreateDate": "2022-08-11T15:11:21+00:00", "UpdateDate": "2022-08-11T15:11:21+00:00" } }# On attache la stratégie "S3_monSQLServer2022" à l'utilisateur IAM "monSQLServer2022 " C:\Users\lprou>aws iam attach-user-policy --policy-arn arn:aws:iam::018033XXXXXX:policy/S3_monSQLServer2022 --user-name monSQLServer2022 - La communication entre votre serveur SQL et AWS S3 se faisant en HTTPS, le certificat permettant d’accéder au bucket S3 devra être installé dans les magasins du serveur SQL.
III] Mise en oeuvre:
- Une fois tous les prérequis satisfait nous pouvons nous connecter à notre instance hébergée sous SQLServer 2022 via “Microsoft SqlServer Management Studio” (SSMS).
Il faut alors créer nos “Credentials” qui permettront au moteur SqlServer de se connecter à notre bucket S3:
Vous trouverez la documentation pour les méthodes d’accès à un compartiment S3 via un point de terminaison, à savoir s3.MYREGION.amazonaws.com ici:
S3 Méthode d’accès# Création des crédentials de type 'S3 Access Key' cf Create credential CREATE CREDENTIAL [s3://s3.eu-west-3.amazonaws.com/capdata-backupsqlserver] WITH IDENTITY = 'S3 Access Key', SECRET = 'AKIAQIMXBNKBG4BLUJUP:7TSSsJ5XQVjze4+HI22Am35eeEax3uQfAsOryPj5'; Attention le caractère séparant l'AccessKeyId du SecretAccessKey dans le secret doit être un ':'

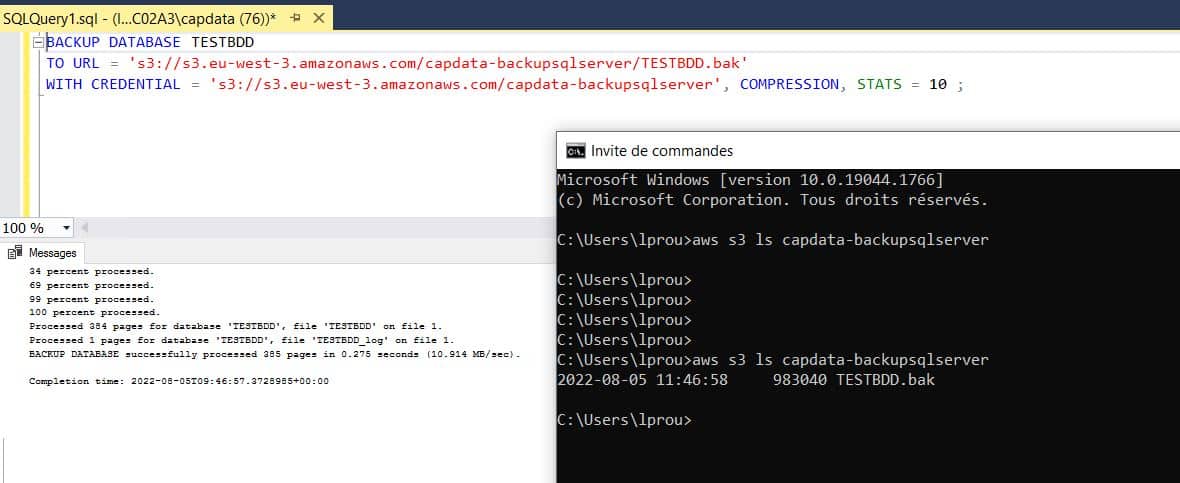
- Ne reste plus qu’à lancer une commande de sauvegarde directement dans notre bucket S3:
# Lancement d'une sauvegarde BACKUP DATABASE TESTBDD TO URL = 's3://s3.eu-west-3.amazonaws.com/capdata-backupsqlserver/TESTBDD.bak' WITH CREDENTIAL = 's3://s3.eu-west-3.amazonaws.com/capdata-backupsqlserver', COMPRESSION, STATS = 10 ;

ou alors sur un access point afin de pouvoir par exemple gérer une stratégie d’accès par applicatif dans le cas ou plusieurs applications écriraient dans le même bucket S3.
cf S3 access point# Lancement d'une sauvegarde BACKUP DATABASE TESTBDD TO URL = 's3://s3.eu-west-3.amazonaws.com/capdata-backupsqlser-ftpz1exz9apnsi9cb1834kq8htfsneuw3b-s3alias/TESTBDD2.bak' WITH CREDENTIAL = 's3://s3.eu-west-3.amazonaws.com/capdata-backupsqlserver', COMPRESSION, STATS = 10 ;

Notes:
Il est bien sûr recommandé d’utiliser un nom de fichier unique pour chaque sauvegarde dans le but d’éviter l’écrasement d’une sauvegarde précédente.
On constate que l’URL contient le nom du Bucket S3 ou l’alias de point d’accès ainsi que la région sur laquelle il a été créé.
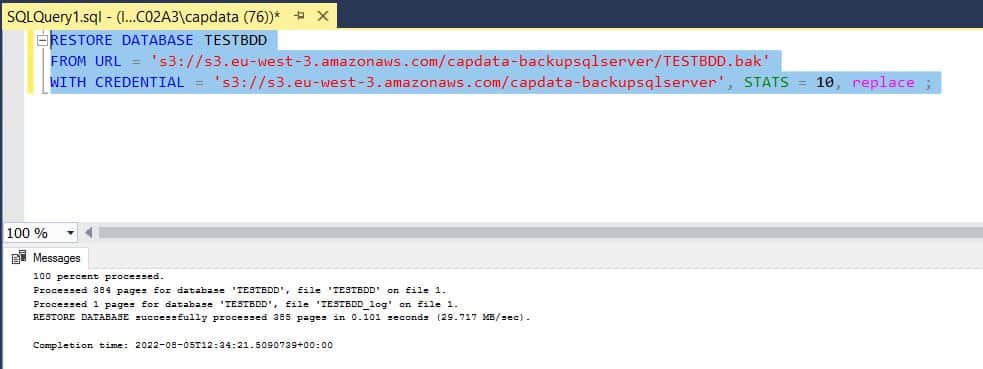
cf S3 Méthode d’accès à un compartiment - On peut naturellement lancer une commande de restauration depuis notre bucket S3:
# Lancement d'une restauration RESTORE DATABASE TESTBDD FROM URL = 's3://s3.eu-west-3.amazonaws.com/capdata-backupsqlserver/TESTBDD.bak' with replace ;

A noter que contrairement à ce qui a pu être vu dans cet article précèdent sauvegardes-sql-server-dans-un-azure-blob-storage,
il n’est pas possible de réaliser une sauvegarde qui soit sur deux emplacements, l’un local et l’autre sur S3 pour l’instant…
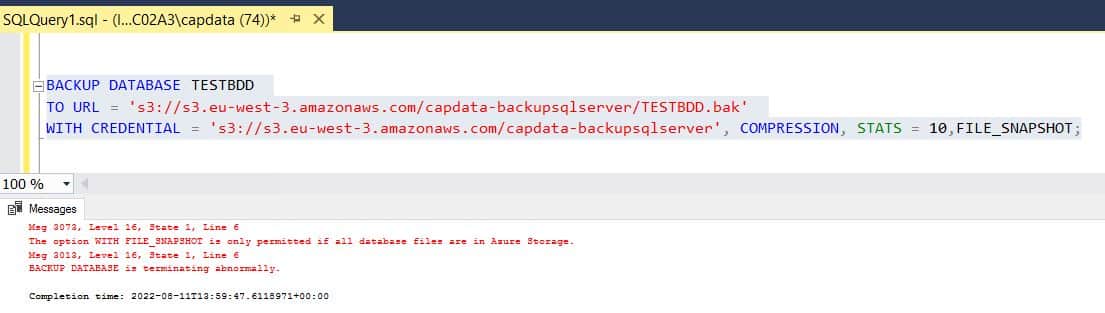
Il n’est pas non plus possible de faire une sauvegarde avec l’option FILE_SNAPSHOT qui n’est pas compatible avec S3 mais juste avec Azure Storage:
cf file-snapshot-backups# Lancement d'une sauvegarde avec FILE_SNAPSHOT impossible BACKUP DATABASE TESTBDD TO URL = 's3://s3.eu-west-3.amazonaws.com/capdata-backupsqlserver/TESTBDD.bak' WITH CREDENTIAL = 's3://s3.eu-west-3.amazonaws.com/capdata-backupsqlserver', COMPRESSION, STATS = 10,FILE_SNAPSHOT;

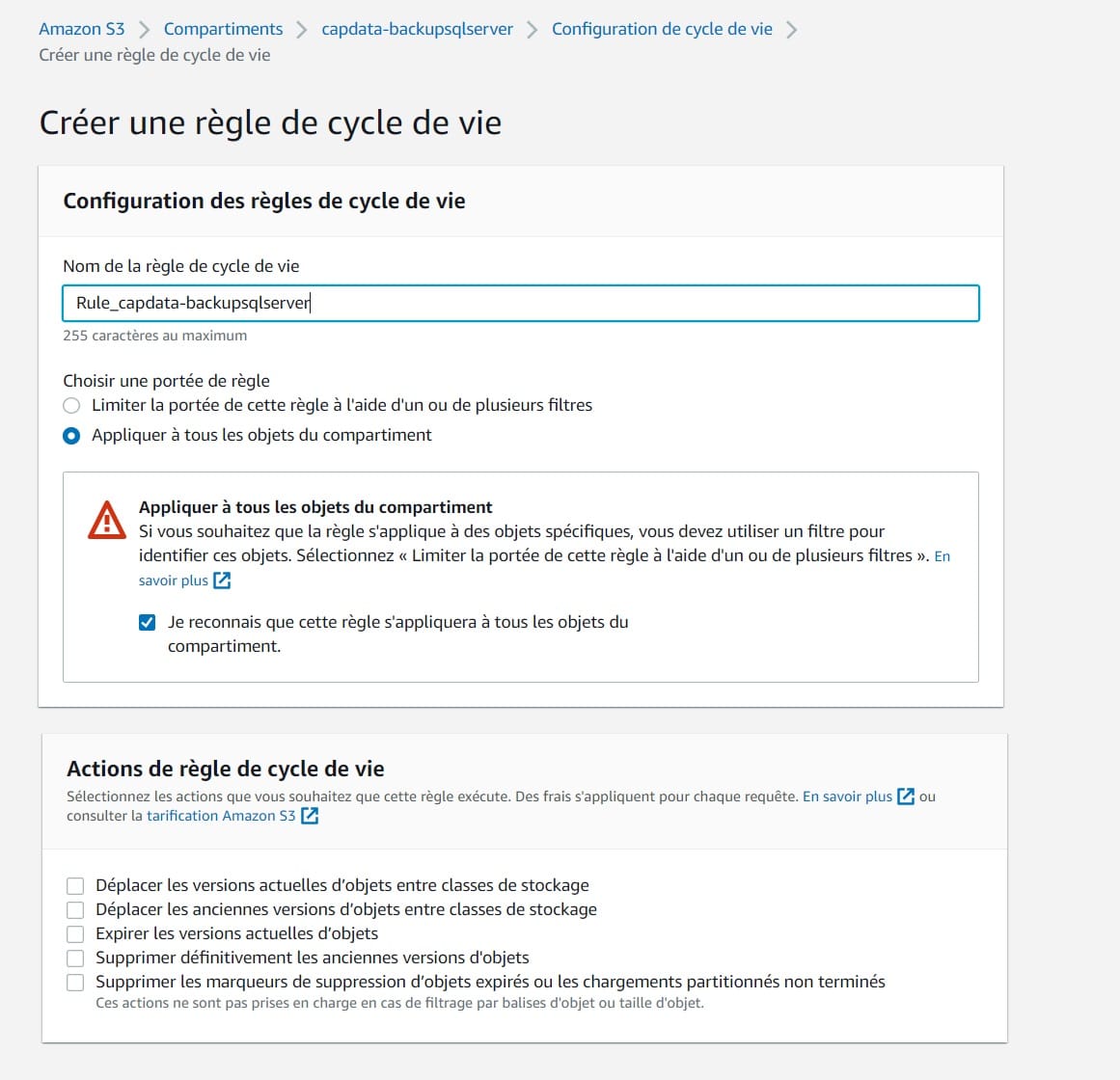
- Enfin il ne reste plus qu’à gérer la rétention de vos sauvegardes en fonction de votre politique de sécurité via une règle de cycle de vie sur votre bucket S3. Vous pouvez également faire un changement de classe de vos vieilles sauvegardes pour les déplacer par exemple sur du Glacier afin de limiter les coûts de stockage.
cf Règle cycle de vie
cf Classes de stockage S3



IV] Conclusion:
Avec cette fonctionnalité de sauvegarder directement depuis sqlServer vers du stockage S3, il devient très facile et très compétitif en terme de coûts d’externaliser ces données. Fini les sauvegardes du we tombées en erreurs en raison d’un manque d’espace disque disponible. Fini également la crainte de perdre ses sauvegardes car AWS garanti leur disponibilité jusqu’à 99,99% pour la classe standard avec une résilience incluse dans la brique S3 qui se base sur la réplication du bucket sur des périphériques de stockage appartenant au moins à trois zones de disponibilités différentes sur une région sélectionnée. Chaque zone étant localisées dans des endroits distincts, la fiabilité en cas de défaillance du matériel de stockage ou de problèmes divers tel qu’un incendie est assurée. Ce niveau de disponibilité dépend bien évidement de la classe de stockage utilisée et à un impact sur le coût de la solution.
Documentations diverses:
https://docs.microsoft.com/en-us/sql/relational-databases/backup-restore/sql-server-backup-and-restore-with-s3-compatible-object-storage?view=sql-server-ver16
https://docs.microsoft.com/en-us/sql/relational-databases/backup-restore/sql-server-backup-to-url-s3-compatible-object-storage?view=sql-server-ver16
https://docs.microsoft.com/en-us/sql/relational-databases/backup-restore/sql-server-backup-to-url-s3-compatible-object-storage-best-practices-and-troubleshooting?view=sql-server-ver16
https://aws.amazon.com/fr/s3
https://aws.amazon.com/fr/s3/pricing/
Continuez votre lecture sur le blog :
- AWS : Backup Restore SQL Server RDS vers une EC2 ou On-Premise et vice versa ! (Emmanuel RAMI) [AWSSQL Server]
- Export d’une VM d’un ESX vers une EC2 AWS (Emmanuel RAMI) [AWS]
- SQL Server 2022 : stockage S3 sans AWS et fichiers Parquet (Capdata team) [AWSSQL Server]
- Oracle RDS : effectuer des backup RMAN en mode PaaS. (Emmanuel RAMI) [AWSNon classéOracle]
- Sauvegardes SQL Server dans un Azure Blob Storage (Capdata team) [AzureSQL Server]
Hello
bon article !!
Et je rajouterais, externalisation et archivage assurée avec S3 Infrequent access et Glacier. Top pour sauvegardes de bases comportant des données comptables sur plusieurs années !