
TDE ou Transparent Data Encryption est un produit mis à disposition par Cybertec. Il permet de faire de l’encryption de données de manière automatique dans Postgres. Il crypte les données des tables, des indexes, les tablespaces, les fichiers temporaires, et tous les objets dépendants de la base de données.
L’encryption est réalisée sur des blocs de 8K entre le disque et la mémoire.
Il utilise toutes les optimisations possibles fournies par Intel pour fonctionner de manière efficace.
Installation :
Pour pouvoir disposer de cet outil, il vous faut disposer de la version de postgres recompilée par Cybertech.
Les sources sont disponibles à l’adresse suivante : https://download.cybertec-postgresql.com/postgresql-12.3_TDE_1.0.tar.gz
wget https://download.cybertec-postgresql.com/postgresql-12.3_TDE_1.0.tar.gz
Une fois les sources téléchargées, vous pouvez les décompresser.
tar xvfz postgresql-12.3_TDE_1.0.tar.gz
L’étape suivante est l’étape de compilation. Pour que votre code puisse être compilé, vous allez avoir besoin d’un certain nombre de prérequis. Ces paquets pré requis sont les mêmes que les paquets nécessaires pour compiler le code de postgresql.
./configure --prefix=/usr/local/pg12tde --with-openssl --with-perl \ --with-python --with-ldap
Une fois la compilation réalisée, il faut installer les sources.
make install cd contrib make install
A la suite de l’installation des sources, vous allez donc vous retrouver avec un dossier pg12tde qui contiendra les sources de postgresql.
Charge à vous de créer l’utilisateur postgres :
addgroup postgres adduser postgres
Et de créer le répertoire où vous souhaitez stocker vos données. Attention, ne démarrez pas votre instance dès à présent.
mkdir -p /usr/local/pg12tde/data chown postgres /usr/local/pg12tde/data
Avant de réaliser l’initialisation de la base de données, vous devez définir l’encryptage de votre base de données. Pour l’exemple, nous avons utilisé une méthode très simple : Un fichier de script qui renvoie directement la clé d’encryptage de nos fichiers de données. Il se présente sous la forme suivante : (vous pouvez cliquer pour agrandir)

Attention : Il s’agit ici d’un exemple simpliste afin de démontrer le fonctionnement de TDE. Dans un environnement de production, il faudra favoriser un serveur de clé KMS type Hashicorp ou autre.
Une fois le fichier de clé clairement identifié, vous pouvez passer en utilisateur postgres et faire le initdb pour créer votre base de données. C’est dans cette commande la que vous allez pouvoir passer votre clé encodée à l’aide de l’option -K. (vous pouvez cliquer pour agrandir)
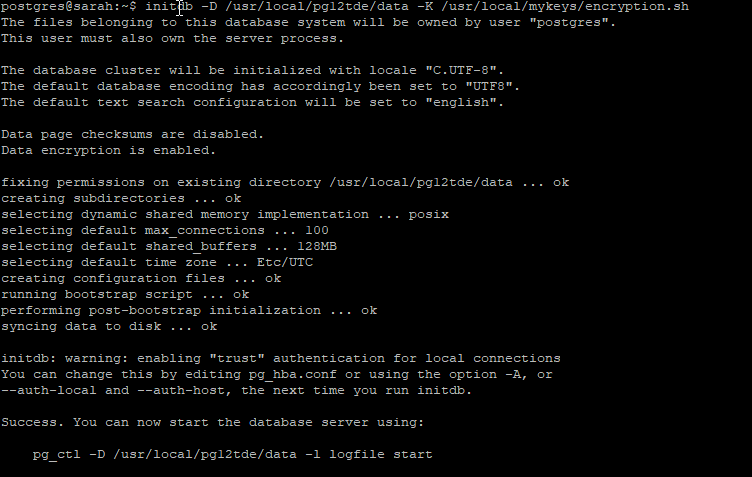
Vous pouvez vérifier qu’il a bien prit le fichier d’encryption en allant jeter un oeil au postgresql.conf (vous pouvez cliquer pour agrandir)

Une fois votre initdb terminé, vous n’avez plus qu’à lancer l’instance, et à vous connecter pour profiter d’un PG encrypté.
Pour l’exemple, nous allons créer une base de données fictive, une table fictive, et des données fictives, et nous allons vérifier l’état du fichier de données, afin de voir si nous pouvons le décrypter. (vous pouvez cliquer pour agrandir)
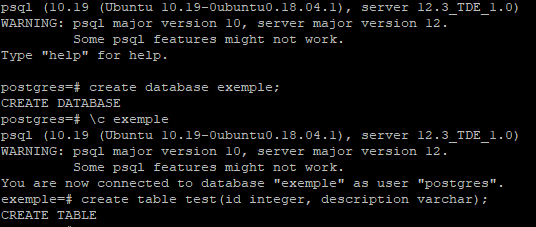

Pour cela il suffit d’aller voir dans le répertoire data de l’instance, et de chercher à ouvrir l’un des fichiers. Vous devriez obtenir un résultat tel que ci-dessous : (vous pouvez cliquer pour agrandir)

On voit donc bien que nos fichiers sont cryptés.
Attention cependant : l’encryption n’est pas effective sur les dumps de données. En effet, extraire des données avec pg_dump ne rentre pas dans la couverture de TDE, contrairement à pg_basebackup.
Nous avons testé de réimporter un pg_basebackup depuis une base cryptée avec TDE vers une base vanilla et cette dernière n’est pas parvenue à lire le fichier de backup.
Au niveau des performances :
L’éditeur parle d’un gap de 30% de performance au maximum avec l’utilisation de TDE par rapport à une version vanilla de postgres.
Nous avons réalisé des tests avec pgbench, et voici les résultats.
La volumétrie de la base choisie est la suivante : (vous pouvez cliquer pour agrandir)
![]()
Cette volumétrie à été choisie par rapport à la taille de la mémoire sur la machine où les tests ont été réalisés. Il s’agissait ici de forcer des lectures et écritures physiques afin de réellement constater l’impact de TDE sur les performances.
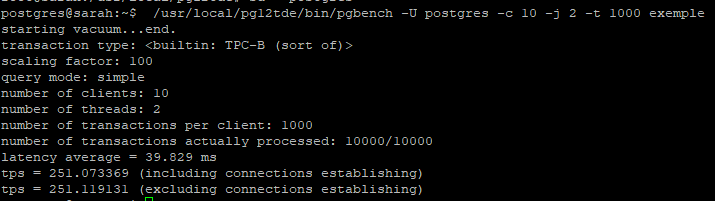
Avec TDE, j’ai réalisé un premier tir avec une génération de 1000 requêtes sur 10 threads différents qui appellent la base en même temps. La capture d’écran qui suit montre le résultats de pgbench en terme de temps de réponse de la simulation : (vous pouvez cliquer pour agrandir)
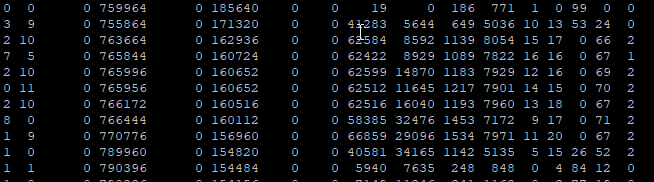
Pendant que la simulation était en cours, nous surveillons également l’activité du serveur grâce à une commande VMstat afin de voir en temps réel la consommation de pgbench en terme de ressources: (vous pouvez cliquer pour agrandir)
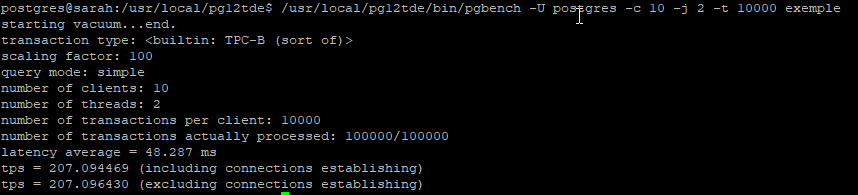
Afin de pouvoir faire une moyenne de temps d’exécution, nous avons lancé une deuxième fois pgbench mais cette fois-ci sur un plus gros échantillon de requêtes afin de mettre encore plus la base de données sous tension. Il s’agissait ici d’un test de 10.000 requêtes sur 10 threads (100.000 requêtes) : (vous pouvez cliquer pour agrandir)
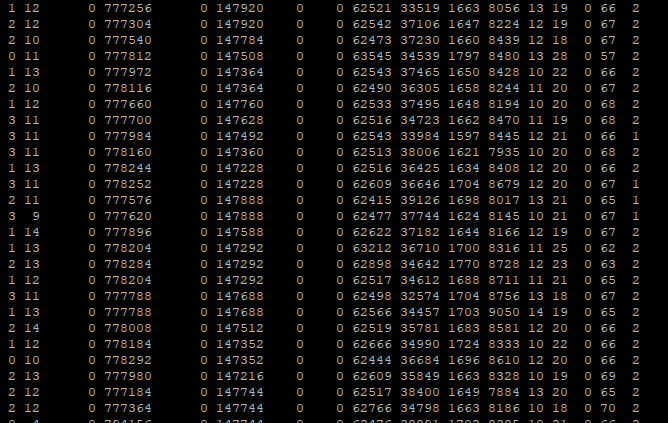
Et comme pour l’essai précédent, nous surveillons l’état du serveur avec VMStat pour constater les pics d’utilisation de pgbench sur les ressources système : (vous pouvez cliquer pour agrandir)
Deuxième étape de notre test, afin de comparer les résultats obtenus, nous avons réaliser les mêmes test avec la même volumétrie sur une installation classique de postgresql. (vous pouvez cliquer pour agrandir)
![]()
Pour le plus petit échantillon de requêtes (les 1000 sur 10 threads) voici les temps de réponses que nous avons obtenus avec pgbench : (vous pouvez cliquer pour agrandir)

Pareillement que pour la première partie du test, nous avons vérifier les consommations système de pgbench : (vous pouvez cliquer pour agrandir)

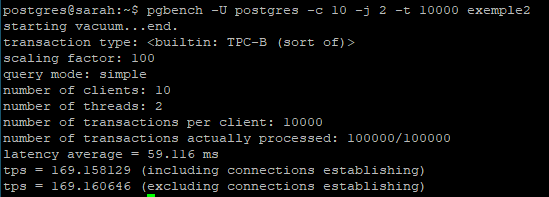
Et enfin, comme pour la première partie, nous avons réaliser le même test avec une volumétries de requêtes envoyées supérieures (100.000 requêtes) : (vous pouvez cliquer pour agrandir)
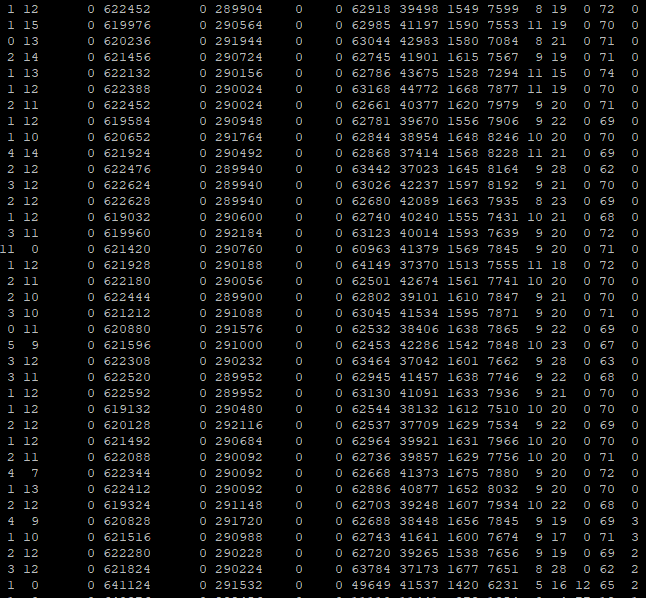
Et le résultat sur vmstat : (vous pouvez cliquer pour agrandir)
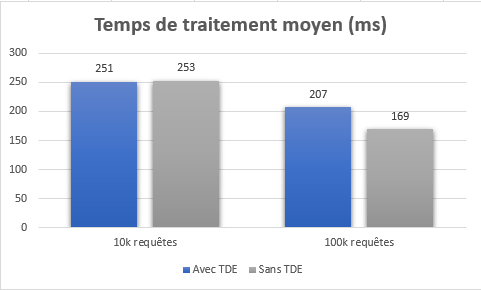
On constate donc qu’il y a bien une différence, surtout sur les traitements d’un grand nombre de données. L’instance vanilla a une moyenne de traitement à 169 ms tandis que l’instance TDE a une moyenne à 207 ms. Ce qui représente quand même une augmentation du temps de traitement de l’ordre de 22%. (vous pouvez cliquer pour agrandir)
Conclusion :
TDE est un outil pratique pour l’encryption des données. Il est relativement facile à configurer, pour peu que vous acceptiez d’utiliser une version fournie par Cybertech que vous devez compiler vous-même.
Il faut cependant garder en mémoire que sur des traitements conséquents, les performances peuvent être impacté de l’ordre de 30%.
Continuez votre lecture sur le blog :
- PostgreSQL 14 et le scram-sha-256 (Sarah FAVEERE) [PostgreSQL]
- Pyrseas et Postgresql : Comparer facilement des schémas de base de données (Sarah FAVEERE) [PostgreSQL]
- Le chiffrement Oracle : Transparent Data Encryption sur Oracle 19c (Emmanuel RAMI) [Oracle]
- Le chiffrement et SQL Server – Episode 1 : Transparent Data Encryption (TDE) vs Always Encrypted (Capdata team) [SQL Server]
- PostgreSQL : planifier une tâche avec pg_cron (Emmanuel RAMI) [Non classéPostgreSQL]