
I] Introduction:
Terraform est une application dite “stateful”. C’est-à-dire que toutes les modifications apportées à votre infrastructure via cet outil sont stockées dans un fichier State (état) au format json nommé terraform.tfstate. Ce fichier est créé lors de la première exécution de votre code terraform et par défaut positionné localement au même endroit que votre code terraform.
A chaque exécution suivante via un terraform apply par exemple, le fichier terraform.tfstate représentant alors l’état dans lequel doit se trouver votre infrastructure est comparé à votre code terraform afin d’en déduire les ajouts (to add), changements (to change), suppression (to destroy) à apporter et donc d’établir son plan. Terraform positionnera une sauvegarde de l’état précédent dans un fichier nommé cette fois-çi terraform.tfstate.backup avant d’apporter les modifications au fichier d’état courant terraform.tfstate.
Cet état est donc très important et nous allons voir dans cet article comment l’externaliser sur un bucket (compartiment) S3 via la notion de remote backend afin de le rendre disponible à chacun tout en le préservant d’une perte accidentelle. Nous utiliserons également une table DynamoDB qui servira à verrouiller le fichier en écriture afin d’éviter un accès concurrentiel; c’est-à-dire que plusieurs process/personnes ne puissent pas apporter des modifications au même moment à votre infrastructure. En effet il est vital avant chaque exécution, de s’assurer de bien disposer des dernières données d’état et d’être le seul à y apporter des modifications à l’instant T. C’est pourquoi le stockage centralisé s’impose et choisir le service AWS S3 offre plusieurs fonctionnalités intéressantes.
A noter qu’en environnement DevOps il est primordial d’éviter tant que faire se peut la déduplication de son code, l’on va donc s’intéresser à la fonctionnalité des Workspaces.
II] Contexte:
Notre objectif ici est de proposer une solution permettant d’automatiser la création\mise à jour\suppression d’une instance EC2 dans un environnement bac à sable AWS. Les objets de type VPC, subnet, security group seront déjà provisionnés. Pour l’instant cela reste simple et votre code terraform pourrait alors ressembler à ceci:
terraform {
required_providers {
aws = {
source = "hashicorp/aws"
version = "~> 4.0"
}
}
}
provider "aws" {
region = var.AWS_REGION
access_key = var.AWS_ACCESS_KEY
secret_key = var.AWS_SECRET_KEY
}
resource "aws_instance" "mon_ec2"{ # Nom que l'on donne à notre ressource pour terraform (à ne pas confondre avec le tag Name de l'EC2)
ami = var.AMI
instance_type = var.INSTANCE_TYPE
tags = {
Name = "${var.TAG_NAME}"
AUTEUR = "${var.TAG_AUTEUR}"
DESCRIPTION = "${var.TAG_DESCRIPTION}"
ENVIRONNEMENT = "${var.TAG_ENVIRONNEMENT}"
}
key_name = var.KEY_NAME
subnet_id = var.SUBNET_ID
vpc_security_group_ids = var.VPC_SECURITY_GROUP_IDS
disable_api_termination = true
}
On définit notre provider AWS, et l’on renseigne nos paramètres d’identification (inutile si vous avez déployé AWS CLI et fait un aws configure ou mieux que vous utilisiez un rôle IAM). Ensuite on défini une ressource de type “aws_instance” (=EC2) que l’on nommera pour terraform “mon_ec2”
On constate qu’un certain nombre de paramètres sont naturellement variabilisés via les fichiers variables.tf et terraform.auto.tfvars. Notamment pour l’identifiant de l’AMI à utiliser, le type d’instance (ex:T2.micro) ainsi que la génération de certains tags etc. Il n’y a plus qu’à exécuter notre code terraform via les commandes terraform plan pour afficher dans un premier temps le plan d’action puis un terraform apply pour créer la ressource de type instance EC2 sur notre environnement AWS.

Sans surprise notre EC2 a bien été créée.
Les jours passent et je voudrais à nouveau créer une EC2 de la même manière mais à partir d’une nouvelle AMI. J’effectue alors quelques modifications au niveau de mes variables pour changer la valeur de var.AMI (ami-09155d2e27d9fb18c) ainsi que var.Name (EC2_TESTLPRTERRAFORM_EC2_2) puis j’exécute à nouveau mon code en espérant avoir une deuxième EC2 !
Et là vous l’aurez compris terraform étant stateful, il détecte qu’il a déjà créé une ressource nommée dans le code terraform “aws_instance” “mon_ec2” via son fichier terraform.tfstate et me propose de la détruire (1 to destroy) pour en ajouter une nouvelle (1 to add) à partir cette fois d’une autre image AMI et de changer le tag Name au passage (c’est bien le changement d’AMI qui explique la destruction puis recréation et pas le changement de tag Name) !
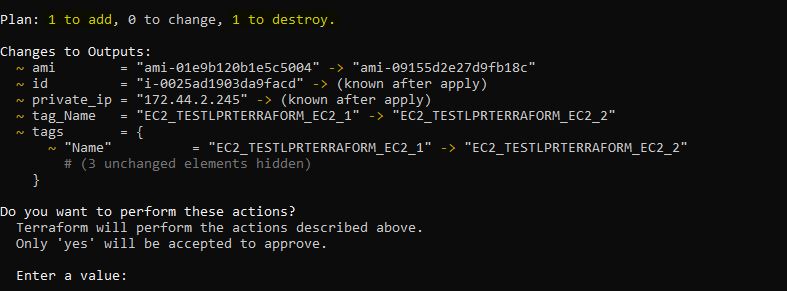
Ce comportement est tout à fait normal car c’est la philosophie même de Terraform. Malheureusement nous ne souhaitons en aucun cas supprimer l’EC2 précédemment créée.
La question est donc de trouver le moyen de réexécuter ce même code (un nombre indéfini de fois d’ailleurs) pour obtenir une nouvelle EC2 à chaque fois mais sans toucher aux autres précédemment créées et tout en garantissant l’intégrité du fichier terraform.tfstate qui pour l’instant est stocké en local.
A noter qu’il est inutile d’essayer de variabiliser le nom de la ressource Terraform afin d’espérer arriver à vos fins, ce n’est pas possible.
# Ne fonctionne pas !
resource "aws_instance" "${var.RESOURCE_NAME}" {
[...]
}III] Prérequis:
- Les binaires Terraform CLI (1.3.7)
- Les binaires AWS CLI (2.9.18)
- 1 Bucket S3 (pour centraliser les fichiers d’état)
- 1 Table dynamoDB (pour gerer les verrous sur les fichiers d’état)
IV] “Arborescence” Terraform actuelle:

IV] “Arborescence” Terraform cible:
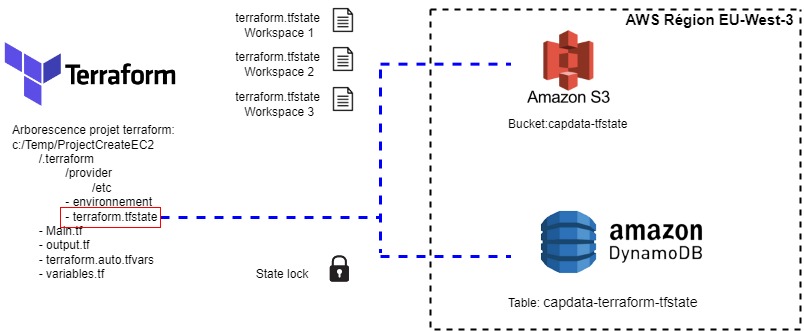
L’une des approches nous permettant de réexécuter exactement le même code Terraform (moyennant naturellement le changement de nos variables) pour gérer des ressources différentes est d’utiliser la fonctionnalité Workspaces de Terraform.
Ces derniers permettent en effet de générer des fichiers d’états (terraform.tfstate) différents pour un même code d’exécution Terraform en les rangeant par Workspaces. C’est-à-dire qu’il suffira avant chaque exécution de notre même code de se positionner sur un nouveau Workspace afin d’obtenir des fichiers d’état distinctes. De cette manière Terraform pourra gérer plusieurs ensembles de ressources qui n’interfèrent pas entre elles. C’est exactement ce qu’on l’on souhaite faire. Une même configuration Terraform pour “n” fichiers d’états !
Petite aparté:
Dans mes lectures j’ai souvent constaté que cette fonctionnalité était utilisée pour dupliquer des environnements. Par exemple un même fichier main.tf pouvant être joué dans un Workspace nommé “Developpement” afin de réaliser des tests puis ensuite joué dans un autre Workspace nommé cette fois “Production”. Passer d’un Workspace à l’autre tout en jouant sur nos variables permet alors d’obtenir deux environnements différents mais à partir du même code terraform. En effet un seul fichier main.tf sera utilisé pour générer ici deux fichiers terraform.tfstate, un pour chacun des Workspaces.
Attention toutefois la documentation Terraform est assez claire à ce sujet:

https://developer.hashicorp.com/terraform/language/state/workspaces
https://developer.hashicorp.com/terraform/cli/workspaces#use-cases
Hashicorp nous explique alors qu’opter pour la fonctionnalité Workspaces pour gérer nos différents environnements Production / Qualification / Développement peut poser un problème “d’isolation”. En effet utiliser le même code terraform au sein de différents Workspaces implique de n’utiliser qu’un seul backend S3 (= bucket S3). Au niveau du schéma “IV] Architecture cible”, on constate bien que l’intégralité de nos fichiers terraform.tfstate correspondant à chacun de nos Workspaces (=environnements de production, qualification et développement) vont se retrouver au même endroit. Il n’y a donc aucune séparation au niveau stockage S3.
Si vos contraintes en terme de sécurité ne sont pas trop élevées cela me semble tout à fait jouable sinon il faudra se pencher sur une gestion via par exemple l’utilisation de différentes branches GIT (avec malheureusement déduplication de votre code qui devra être maintenu à jour entre les différentes branches…) ou alors éventuellement utiliser un autre outil nommé Terragrunt (wrapper pour terraform) évitant justement la déduplication de code.
V] Mise en oeuvre:
Passons à la mise en œuvre afin d’illustrer le concept:
A- Commençons par créer notre bucket S3 qui va héberger l’ensemble de nos fichiers d’états (terraform.tfstate):
# Consultation de l'aide de la commande create-bucket
C:\Users\lprou>aws s3api create-bucket help
# Création du compartiment S3
C:\Users\lprou>aws s3api create-bucket --bucket capdata-tfstate --region eu-west-3 --create-bucket-configuration LocationConstraint=eu-west-3 --acl private
# Désactivation de l'accès publique
C:\Users\lprou>aws s3api put-public-access-block --bucket capdata-tfstate --public-access-block-configuration "BlockPublicAcls=true,IgnorePublicAcls=true,BlockPublicPolicy=true,RestrictPublicBuckets=true"
# Activation du chiffrage
C:\Users\lprou>aws s3api put-bucket-encryption --bucket capdata-tfstate --server-side-encryption-configuration "{\"Rules\": [{\"ApplyServerSideEncryptionByDefault\":{\"SSEAlgorithm\": \"AES256\"}}]}"
# Activation du versionning afin de conserver un historique de nos fichiers terraform.tfstate
C:\Users\lprou>aws s3api put-bucket-versioning --bucket capdata-tfstate --versioning-configuration MFADelete=Disabled,Status=Enabled
Terraform aura besoin des droits suivants sur le bucket S3 (cf S3 Bucket Permissions):
s3:ListBucket
s3:GetObject
s3:PutObject
s3:DeleteObject
A noter qu’il est possible en environnement critique d’activer la réplication de votre bucket S3:
https://docs.aws.amazon.com/fr_fr/AmazonS3/latest/userguide/replication.html
Et également de mettre en place une règle de cycle de vie pour faire du ménage concernant les anciennes versions de vos fichiers terraform.tstate: https://docs.aws.amazon.com/fr_fr/AmazonS3/latest/userguide/object-lifecycle-mgmt.html
B- Continuons par créer notre table DynamoDB qui hébergera les informations de verrouillage des fichiers terraform.tfstate:
# Consultation de l'aide de la commande create-table C:\Users\lprou>aws dynamodb create-table help # Création d'une table DynamoDB C:\Users\lprou>aws dynamodb create-table --table-name capdata-terraform-tfstate --attribute-definitions AttributeName=LockID,AttributeType=S --key-schema AttributeName=LockID,KeyType=HASH --provisioned-throughput ReadCapacityUnits=1,WriteCapacityUnits=1 --table-class STANDARD # Configuration des capacités d'autoscaling en écriture C:\Users\lprou>aws application-autoscaling register-scalable-target --service-namespace dynamodb --scalable-dimension dynamodb:table:WriteCapacityUnits --resource-id table/capdata-terraform-tfstate --min-capacity 1 --max-capacity 10 # Configuration des capacités d'autoscaling en lecture C:\Users\lprou>aws application-autoscaling register-scalable-target --service-namespace dynamodb --scalable-dimension dynamodb:table:ReadCapacityUnits --resource-id table/capdata-terraform-tfstate --min-capacity 1 --max-capacity 10
Terraform aura besoin des droits suivants table DynamoDB (cf DynamoDB Table Permissions):
dynamodb:DescribeTable
dynamodb:GetItem
dynamodb:PutItem
dynamodb:DeleteItem
C- Création de notre environnement terraform dans notre dossier “ProjectCreateEC2”:
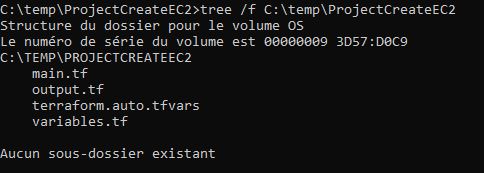
Comme vu un peu plus haut nous disposons d’un dossier nommé c:\temp\ProjectCreateEC2 avec les fichiers suivants:
terraform {
required_providers {
aws = {
source = "hashicorp/aws"
version = "~> 4.0"
}
}
}
provider "aws" {
region = var.AWS_REGION
access_key = var.AWS_ACCESS_KEY
secret_key = var.AWS_SECRET_KEY
}
terraform {
backend "s3" {
bucket = "capdata-tfstate" # nom de notre bucket S3
key = "terraform.tfstate" # nom à utiliser pour les fichiers d'états
region = "eu-west-3"
encrypt = true # paramètre optionnel et je pense inutile ici puisque l'encryption à déjà été positionné sur notre bucket
dynamodb_table = "capdata-terraform-tfstate" # nom de notre table DynamoDB
}
}
resource "aws_instance" "mon_ec2" {
ami = var.AMI
instance_type = var.INSTANCE_TYPE
tags = {
Name = "${var.TAG_NAME}"
AUTEUR = "${var.TAG_AUTEUR}"
DESCRIPTION = "${var.TAG_DESCRIPTION}"
ENVIRONNEMENT = "${var.TAG_ENVIRONNEMENT}"
}
key_name = var.KEY_NAME
subnet_id = var.SUBNET_ID
vpc_security_group_ids = var.VPC_SECURITY_GROUP_IDS
disable_api_termination = true
}Je n’aborderai pas en détail le contenu des autres fichiers mais sachez que:
– terraform.auto.tfvars contient les identifiants AWS
– variables.tf contient les autres variables
– output.tf sert à renvoyer des paramètres de sortie (ex: Adresse IP de l’EC2 créée…)suite à l’exécution de notre code Terraform. Nous avons ainsi la possibilité d’interroger les valeurs d’output présentes dans notre tfstate via la commande:
# Affiche l'aide concernant la commande output
C:\temp\ProjectCreateEC2>terraform output --help
# Récupère uniquement la valeur de l'output nommé private_ip
C:\temp\ProjectCreateEC2>terraform output -raw private_ip
172.44.2.118
# Récupère tout l'output au format json
C:\temp\ProjectCreateEC2>terraform output -json
{
"ami": {
"sensitive": false,
"type": "string",
"value": "ami-01e9b120b1e5c5004"
},
"id": {
"sensitive": false,
"type": "string",
"value": "i-0a572194708a33c46"
}, [...]Une fois la modification effectuée il faut réinitialiser notre dossier de travail Terraform ProjectCreateEC2 afin qu’il puisse prendre en compte notre remote backend, sinon vous obtiendrai l’erreur suivante:
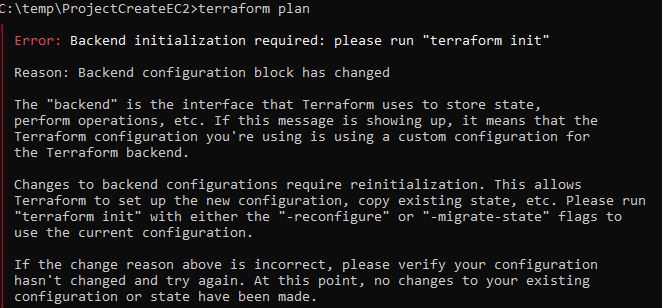
En effet un terraform init est obligatoire à chaque changement au niveau du provider, backend ou modules.
Il nous explique alors qu’il est possible de jouer avec la commande terraform init -reconfigure ou -migrate-state.
Vous pouvez également vous contentez de faire du ménage dans le dossier c:\temp\ProjectCreateEC2 en supprimant le dossier .terraform qui contient les informations d’initialisation ainsi qu’en supprimant le fichier .terraform.lock.hcl. Ce dernier permet justement à Terraform de suivre les modifications apportées au provider, backend et ou modules afin de demander une réinitialisation lors de la prochaine exécution.
Je vous invite vivement à parcourir ce dossier et ouvrir les fichiers qu’il contient afin de comprendre le fonctionnement interne de Terraform ;).
Une fois le ménage effectué, je lance donc une nouvelle initialisation de mon dossier c:\temp\ProjectCreateEC2 (cette manipulation équivaut donc à la commande terraform init -reconfigure):
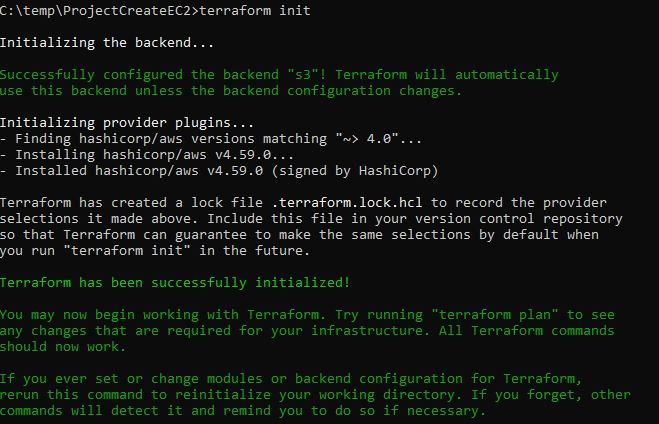
L’initialisation est terminée et notre dossier ressemble désormais à cela:
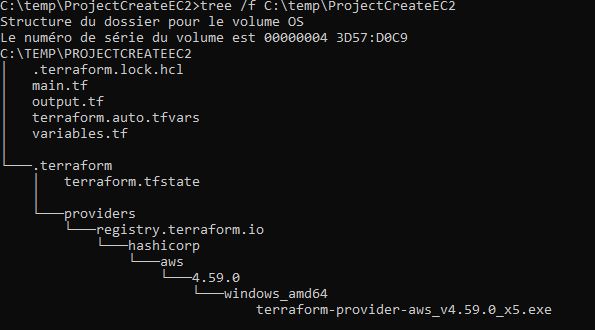
On constate que le fichier d’état n’est plus à la racine de notre dossier ProjectCreateEC2 mais dans le dossier d’initialisation .terraform\terraform.tfstate.
Cela semble étonnant car le but est de le déporter sur notre bucket S3 et surtout que nous n’avons toujours pas créer notre ressource “aws_instance” “mon_ec2” via la commande terraform apply. Donc logiquement aucun fichier d’état ne devrait-être créé ! Ouvrons le pour voir ce qu’il contient:
{
"version": 3,
"serial": 1,
"lineage": "0fbafb73-0882-e174-7f75-cfc706d29c5e",
"backend": {
"type": "s3", # Il s'agit d'un stockage de type S3
"config": {
"access_key": null,
"acl": null,
"assume_role_duration_seconds": null,
"assume_role_policy": null,
"assume_role_policy_arns": null,
"assume_role_tags": null,
"assume_role_transitive_tag_keys": null,
"bucket": "capdata-made-tfstate", # On retrouve le nom de notre bucket S3
"dynamodb_endpoint": null,
"dynamodb_table": "terraform_tfstate", # On retrouve le nom de notre table DynamoDB
"encrypt": true,
"endpoint": null,
"external_id": null,
"force_path_style": null,
"iam_endpoint": null,
"key": "terraform.tfstate", # Le nom du fichier tfstate
"kms_key_id": null,
"max_retries": null,
"profile": null,
"region": "eu-west-3",
"role_arn": null,
"secret_key": null,
"session_name": null,
"shared_credentials_file": null,
"skip_credentials_validation": null,
"skip_metadata_api_check": null,
"skip_region_validation": null,
"sse_customer_key": null,
"sts_endpoint": null,
"token": null,
"workspace_key_prefix": null
},
"hash": 3248788392
},
"modules": [
{
"path": [
"root"
],
"outputs": {},
"resources": {},
"depends_on": []
}
]
}On se rend compte qu’il ne s’agit pas là d’un état à proprement parler mais bien de toutes les informations nécessaires à Terraform pour externaliser les futurs fichiers terraform.tfstate sur notre bucket S3 et utiliser notre table DynamoDB.
D- Création de nos Workspaces:
Il faut donc maintenant s’intéresser à la création d’un Workspace avant d’exécuter notre code qui instanciera notre première instance EC2.
Pour s’y retrouver j’affecte comme nom de Workspace la même valeur que mon tag “Name” (qui lui est variabilisé dans la ressource terraform) de ma future EC2. Une fois créé Terraform bascule automatiquement sur notre nouveau Workspace (présence d’un * en face du workspace courant dans la commande list).
C:\temp\ProjectCreateEC2>terraform workspace new EC2_TESTLPRTERRAFORM_EC2_1 Created and switched to workspace "EC2_TESTLPRTERRAFORM_EC2_1"! # On bascule du Workspace par défaut à celui nouvellement créé You're now on a new, empty workspace. Workspaces isolate their state, so if you run "terraform plan" Terraform will not see any existing state for this configuration. C:\temp\ProjectCreateEC2>terraform workspace list default * EC2_TESTLPRTERRAFORM_EC2_1
Nous sommes donc positionné sur le Workspace EC2_TESTLPRTERRAFORM_EC2_1 et pouvons désormais exécuter notre code d’instanciation d’EC2 (enfin !)
C:\temp\ProjectCreateEC2>terraform apply Terraform used the selected providers to generate the following execution plan. Resource actions are indicated with the following symbols: + create Terraform will perform the following actions: # aws_instance.mon_ec2 will be created + resource "aws_instance" "mon_ec2" { + ami = "ami-01e9b120b1e5c5004" + arn = (known after apply) + associate_public_ip_address = (known after apply) + availability_zone = (known after apply) + cpu_core_count = (known after apply) [...] Plan: 1 to add, 0 to change, 0 to destroy. # Il s'agit bien d'un ajout. Changes to Outputs: + ami = "ami-01e9b120b1e5c5004" + id = (known after apply) + instance_type = "t2.micro" + private_ip = (known after apply) + tag_Name = "EC2_TESTLPRTERRAFORM_EC2_1" + tags = { + "AUTEUR" = "LPR" + "DESCRIPTION" = "EC2 CREEE DEPUIS TERRAFORM" + "ENVIRONNEMENT" = "TEST_TERRAFORM" + "Name" = "EC2_TESTLPRTERRAFORM_EC2_1" } Do you want to perform these actions in workspace "EC2_TESTLPRTERRAFORM_EC2_1"? # Terraform est plutôt sympas il nous confirme le Workspace Terraform will perform the actions described above. sur lequel il va lancer les actions. Only 'yes' will be accepted to approve. Enter a value: yes aws_instance.mon_ec2: Creating... aws_instance.mon_ec2: Still creating... [10s elapsed] aws_instance.mon_ec2: Still creating... [20s elapsed] aws_instance.mon_ec2: Still creating... [30s elapsed] aws_instance.mon_ec2: Creation complete after 32s [id=i-0a14f7ff418babb3c] Apply complete! Resources: 1 added, 0 changed, 0 destroyed. # l'ajout est terminé ! Outputs: # Affichage des variables de sortie comme vu dans la partie C- ami = "ami-01e9b120b1e5c5004" id = "i-0a14f7ff418babb3c" instance_type = "t2.micro" private_ip = "172.44.2.246" tag_Name = "EC2_TESTLPRTERRAFORM_EC2_1" tags = tomap({ "AUTEUR" = "LPR" "DESCRIPTION" = "EC2 CREEE DEPUIS TERRAFORM" "ENVIRONNEMENT" = "TEST_TERRAFORM" "Name" = "EC2_TESTLPRTERRAFORM_EC2_1" })
A noter que vous pouvez maintenant utiliser la variable ${terraform.workspace} dans votre code afin de récupérer le nom du Workspace courant. Pratique pour vos tags (ex: tags = {Name = “${terraform.workspace}”
Et comme l’on ne croit que ce que l’on voit, on vérifie côté AWS la création de notre EC2:
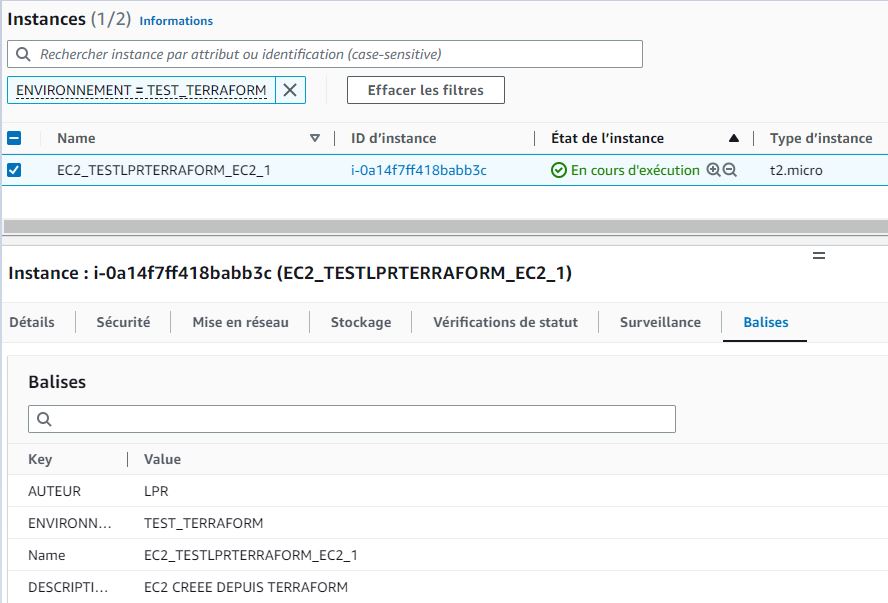
On vérifie éalement que le fichier terraform.tfstate soit bien présent dans notre bucket S3 sous capdata-tfstate/env:/EC2_TESTLPRTERRAFORM_EC2_1 (terraform les range par défaut par nom de Workspace):

Maintenant il n’y-a plus qu’à aller voir votre développeur préféré et lui signaler que sa machine est prête 😉
Ah c’est balo, il vient de se rendre compte que sa demande n’était pas complète et que finalement il veut bien une deuxième machine pour pouvoir s’amuser un peu plus!
Heureusement si vous avez suivi, on a prévu le coup:
Comme on est fainéant on ne touche pas à notre code terraform. Et oui sans Workspaces certains seraient tentés d’ajouter un autre bloc resource “aws_instance” “mon_ec2_bis” {…} dans le main.tf ainsi que de nouvelles variables dans le fichier correspondant. Ou alors dupliquer le dossier c:\temp\ProjectCreateEC2 en c:\temp\ProjectCreateEC2_bis …
Alors qu’il suffit de créer un deuxième Workspace et modifier nos variables au passage:
C:\temp\ProjectCreateEC2>terraform workspace new EC2_TESTLPRTERRAFORM_EC2_2 Created and switched to workspace "EC2_TESTLPRTERRAFORM_EC2_2"! You're now on a new, empty workspace. Workspaces isolate their state, so if you run "terraform plan" Terraform will not see any existing state for this configuration. C:\temp\ProjectCreateEC2>terraform workspace list default EC2_TESTLPRTERRAFORM_EC2_1 * EC2_TESTLPRTERRAFORM_EC2_2
Et c’est reparti:
C:\temp\ProjectCreateEC2>terraform apply
Terraform used the selected providers to generate the following execution plan. Resource actions are indicated with the
following symbols:
+ create
Terraform will perform the following actions:
# aws_instance.mon_ec2 will be created
+ resource "aws_instance" "mon_ec2" {
+ ami = "ami-09155d2e27d9fb18c" # Vous noterez qu'on a changé entre autre l'AMI source via nos variables
+ arn = (known after apply)
+ associate_public_ip_address = (known after apply)
+ availability_zone = (known after apply)
+ cpu_core_count = (known after apply)
[...]
Plan: 1 to add, 0 to change, 0 to destroy. # Il s'agit bien d'un ajout et pas d'un to destroy puis to add
comme vu dans la partie II]
Changes to Outputs:
+ ami = "ami-09155d2e27d9fb18c"
+ id = (known after apply)
+ instance_type = "t2.micro"
+ private_ip = (known after apply)
+ tag_Name = "EC2_TESTLPRTERRAFORM_EC2_2"
+ tags = {
+ "AUTEUR" = "LPR"
+ "DESCRIPTION" = "EC2 CREEE DEPUIS TERRAFORM"
+ "ENVIRONNEMENT" = "TEST_TERRAFORM"
+ "Name" = "EC2_TESTLPRTERRAFORM_EC2_2"
}
Do you want to perform these actions in workspace "EC2_TESTLPRTERRAFORM_EC2_2"? # Nous sommes bien sur notre deuxième Workspace
Terraform will perform the actions described above.
Only 'yes' will be accepted to approve.
Enter a value: yes
aws_instance.mon_ec2: Creating...
aws_instance.mon_ec2: Still creating... [10s elapsed]
aws_instance.mon_ec2: Still creating... [20s elapsed]
aws_instance.mon_ec2: Still creating... [30s elapsed]
aws_instance.mon_ec2: Creation complete after 32s [id=i-021be48a39c34866e]
Apply complete! Resources: 1 added, 0 changed, 0 destroyed. # l'ajout est terminé !
Outputs: # Affichage des variables de sortie comme vu dans la partie C-
ami = "ami-09155d2e27d9fb18c"
id = "i-021be48a39c34866e"
instance_type = "t2.micro"
private_ip = "172.44.2.158"
tag_Name = "EC2_TESTLPRTERRAFORM_EC2_2"
tags = tomap({
"AUTEUR" = "LPR"
"DESCRIPTION" = "EC2 CREEE DEPUIS TERRAFORM"
"ENVIRONNEMENT" = "TEST_TERRAFORM"
"Name" = "EC2_TESTLPRTERRAFORM_EC2_2"
})Notre deuxième EC2 est bien là alors que la première tourne toujours. Ouf on n’a rien cassé aujourd’hui !
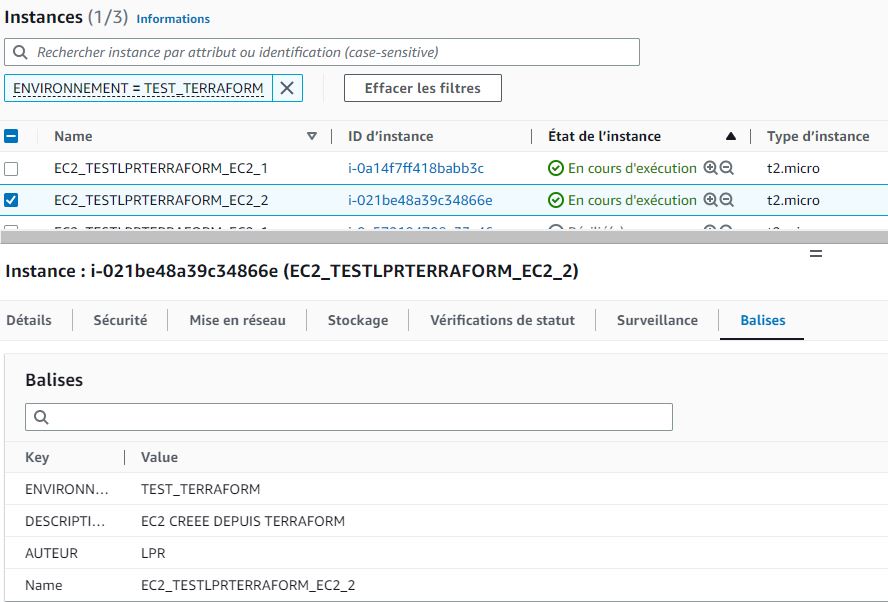
Petite aparté:
J’en profite pour vous signaler qu’il existe “un meta-argument” lifecycle {prevent_destroy = true} à ajouter à votre ressource terraform si vous souhaitez vous protéger d’une destruction accidentelle (cf The Lifecycle meta-argument).
C:\temp\ProjectCreateEC2>terraform plan aws_instance.mon_ec2: Refreshing state... [id=i-021be48a39c34866e] ╷ │ Error: Instance cannot be destroyed │ │ on main.tf line 38: │ 38: resource "aws_instance" "mon_ec2" { │ │ Resource aws_instance.mon_ec2 has lifecycle.prevent_destroy set, but the plan calls for this resource to be │ destroyed. To avoid this error and continue with the plan, either disable lifecycle.prevent_destroy or reduce the │ scope of the plan using the -target flag.
Le deuxième fichier terraform.tfstate est lui aussi bien présent dans notre bucket S3 sous capdata-tfstate/env:/EC2_TESTLPRTERRAFORM_EC2_2
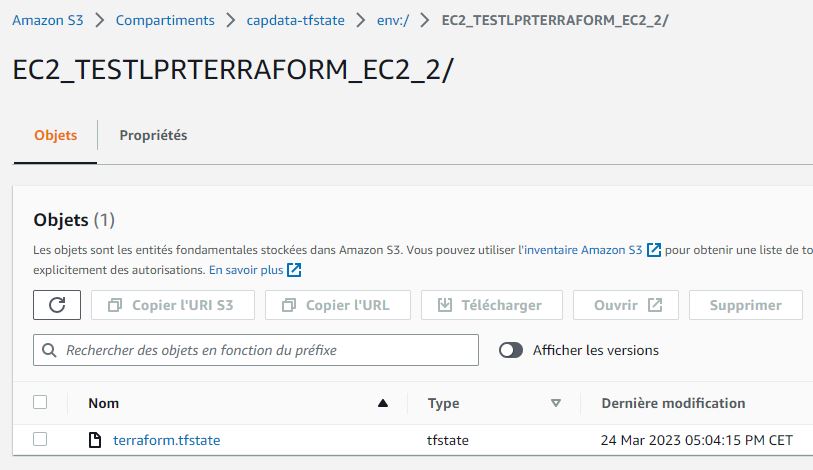
Je vous invite à retourner voir votre développeur préféré pour lui dire que cette fois vous avez bien fini le job!
Malheureusement en passant devant le bureau de votre deuxième développeur préféré ce dernier vous fait part de son sentiment de jalousie…“Mais heu… moi aussi je veux bien une machine”…
Du coup proposez leur de bosser un peu et de développer une application web qui pourrait par exemple permettre de renseigner vos variables, créer un Workspace et lancer votre code Terraform à votre place (terraform apply ainsi que terraform destroy tant qu’à faire). De cette manière ils pourront être autonome à chaque fois qu’ils auront besoin d’un nouvel environnement ;).
VI] Et la table DynamoDB dans tout ça ??:
Effectivement ne me reste plus qu’à vous démontrer l’intérêt d’une table DynamoDB.
J’ouvre ici deux invites dos pour simuler un accès concurrentiel à notre fichier terraform.tfstate correspondant au workspace “EC2_TESTLPRTERRAFORM_EC2_2”
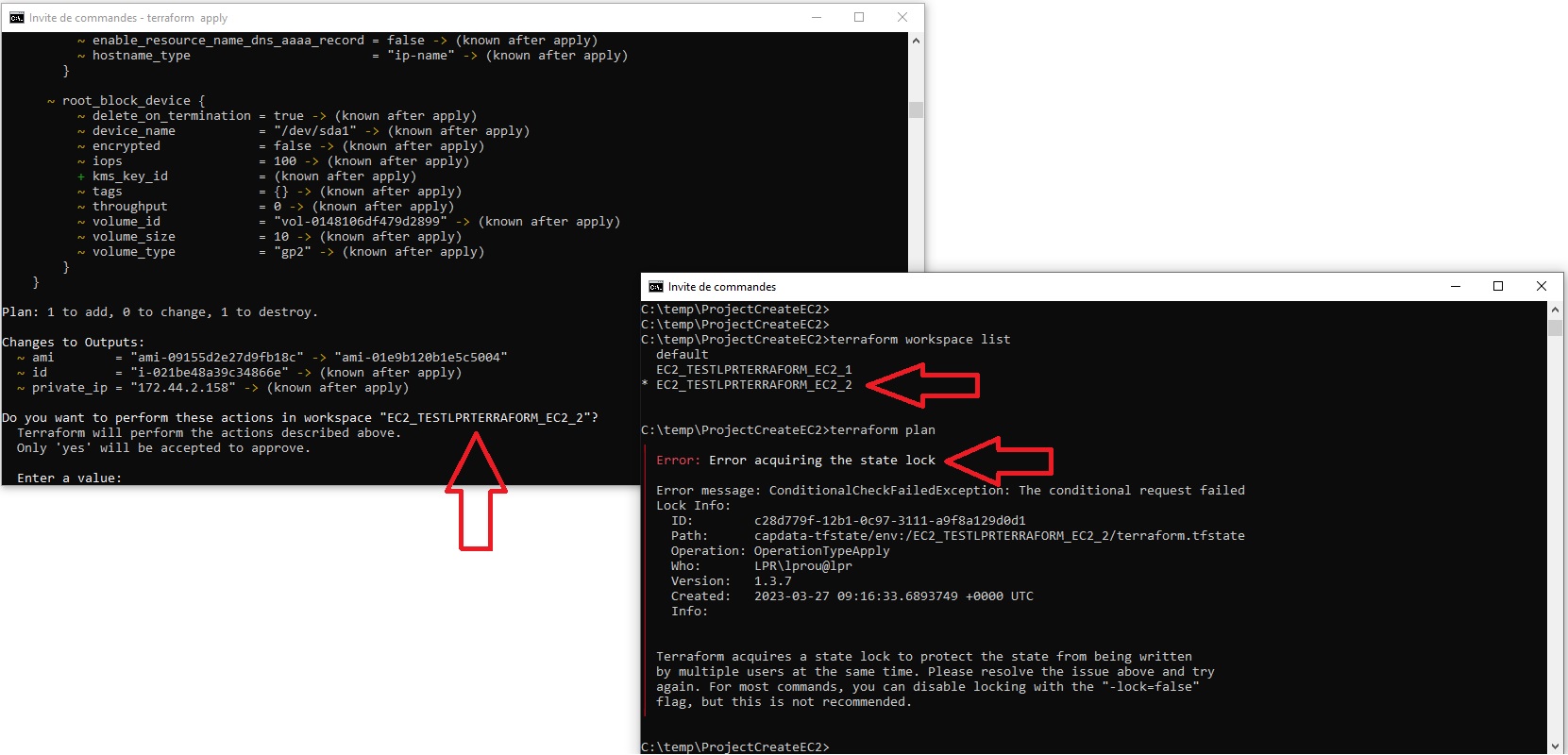
Dans l’invit de gauche j’ai modifié l’AMI source de ma ressource “aws_instance” “mon_ec2” ce qui provoquera naturellement une destruction de l’EC2 actuelle (1 to destroy), pour en créer une autre à partir de la nouvelle AMI (1 to add). On a vu en introduction que pour faire son apply Terraform a besoin de générer un plan et commence donc par consulter son fichier d’état pour le comparer à ce que l’on souhaite réaliser via notre code descriptif. Comme notre remote backend est configuré pour utiliser une table DynamoDB, il ajoute une ligne dans cette dernière pour poser un verrou sur le fichier d’état en question:
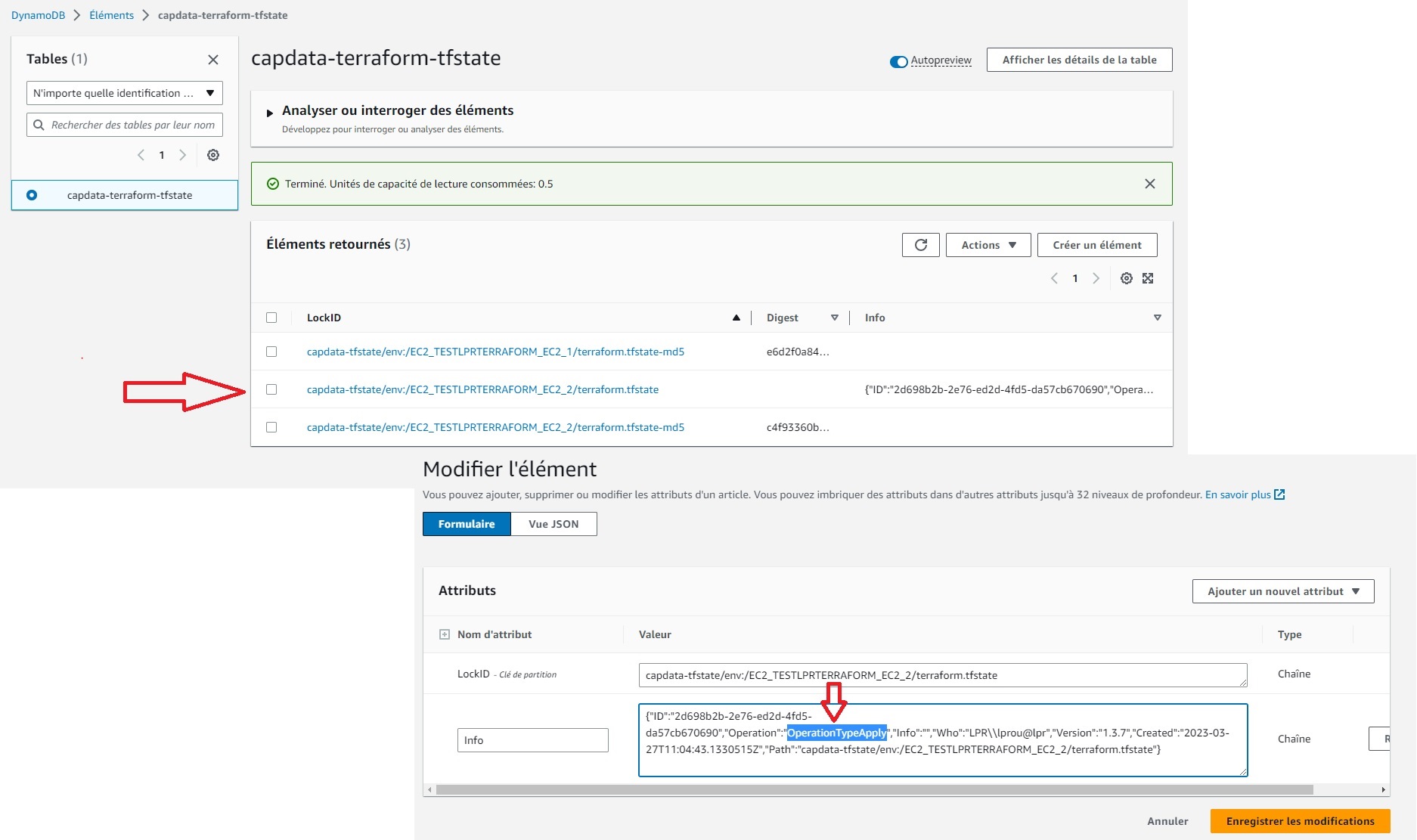
Dans l’invit de droite on constate bien qu’il est impossible d’effectuer la moindre action via ce même fichier d’état. Même un simple terraform plan nous renvoi une erreur. Car en consultant la table DynamoDB Terraform constate qu’un verrou est déjà posé sur le fichier capdata-tfstate/env:/EC2_TESTLPRTERRAFORM_EC2_2/terraform.tfstate. Il nous donne même quelques renseignements supplémentaires concernant notre verrou comme la machine et utilisateur qui l’ont posé, la version de Terraform utilisée ainsi que la date.
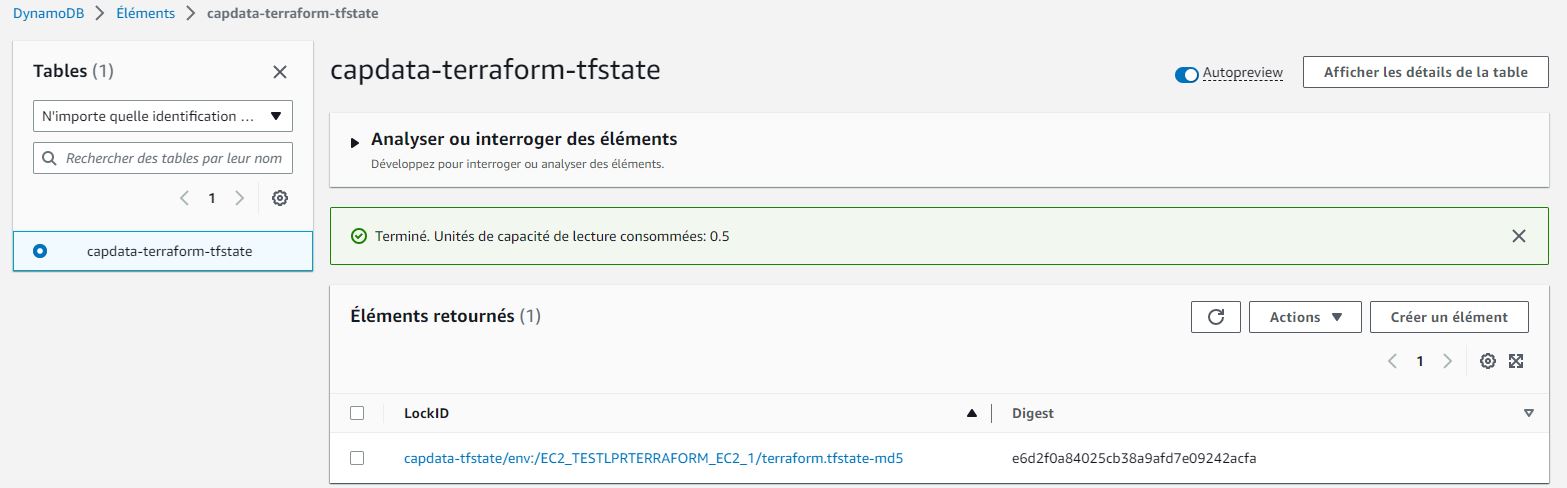
A noter qu’il ne faut pas oublier après un terraform destroy de supprimer notre workspace correspondant afin de faire du ménage au niveau du bucket S3 et de la table DynamoDB:
C:\temp\ProjectCreateEC2>terraform workspace list default EC2_TESTLPRTERRAFORM_EC2_1 * EC2_TESTLPRTERRAFORM_EC2_2 C:\temp\ProjectCreateEC2>terraform workspace select default Switched to workspace "default". C:\temp\ProjectCreateEC2>terraform workspace list * default EC2_TESTLPRTERRAFORM_EC2_1 EC2_TESTLPRTERRAFORM_EC2_2 C:\temp\ProjectCreateEC2>terraform workspace delete EC2_TESTLPRTERRAFORM_EC2_2 Deleted workspace "EC2_TESTLPRTERRAFORM_EC2_2"! C:\temp\ProjectCreateEC2>terraform workspace list * default EC2_TESTLPRTERRAFORM_EC2_1
VII] Conclusion:
Dans cet article, nous avons pu démontrer l’intérêt d’utiliser les Workspaces dans vos projets Terraform, En effet, il faut les voir comme une possibilité d’obtenir plusieurs états différents correspondant à différentes exécutions du même code Terraform. A chaque exécution, il suffit alors de modifier les variables afin de distinguer nos ressources dans notre infrastructure. Beaucoup utilisent alors les Workspaces dans le but de dupliquer des environnements production / développement / qualification par exemple. Cela évite d’avoir à maintenir plusieurs projets Terraform différents (un par environnement).
Ici il s’agissait par exemple d’offrir la possibilité à vos utilisateurs d’instancier leur propre EC2 sur un VPC pré-provisionné côté AWS, de manière complètement automatisé sans avoir à modifier de code Terraform à chaque fois; et de manière native c’est-à-dire sans utiliser aucun autre outils. A part éventuellement la mise en place d’une interface utilisateur type page Web.
Nous comparerons certainement l’utilisation des Workspaces de Terraform à l’utilisation de l’outil tier Terragrunt (qui je le rappel est une “surcouche” à Terraform permettant entre autre d’éviter la déduplication de code) dans un prochain article…
Continuez votre lecture sur le blog :
- SQL Server 2022 Backup / Restore via un bucket S3 sous AWS (Louis PROU) [AWSSQL Server]
- SQL Server 2022 : stockage S3 sans AWS et fichiers Parquet (Capdata team) [AWSSQL Server]
- AWS : Backup Restore SQL Server RDS vers une EC2 ou On-Premise et vice versa ! (Emmanuel RAMI) [AWSSQL Server]
- Nouveautés pg_stat_statements avec PostgreSQL 15 (David Baffaleuf) [PostgreSQL]
- Export d’une VM d’un ESX vers une EC2 AWS (Emmanuel RAMI) [AWS]
Très utile pour configurer Workspaces Terraform avec S3 et DynamoDB. Plus de conseils sur Telkom University Jakarta.